 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCup Curriculum: Curriculum Learning on Model Capacity
Nov 07, 2023

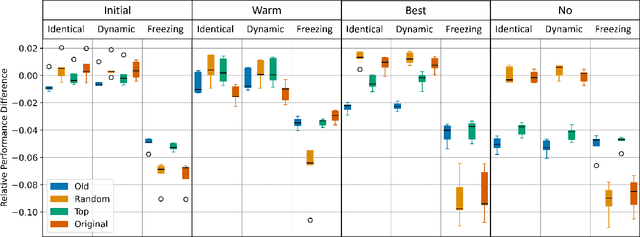
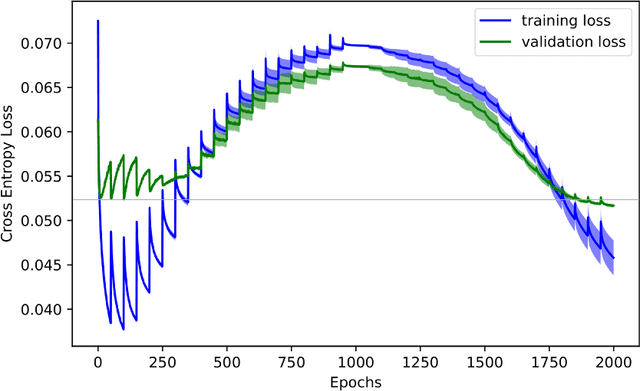
Curriculum learning (CL) aims to increase the performance of a learner on a given task by applying a specialized learning strategy. This strategy focuses on either the dataset, the task, or the model. There is little to no work analysing the possibilities to apply CL on the model capacity in natural language processing. To close this gap, we propose the cup curriculum. In a first phase of training we use a variation of iterative magnitude pruning to reduce model capacity. These weights are reintroduced in a second phase, resulting in the model capacity to show a cup-shaped curve over the training iterations. We empirically evaluate different strategies of the cup curriculum and show that it outperforms early stopping reliably while exhibiting a high resilience to overfitting.