 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext based Analysis of Lexical Semantics for Hindi Language
Jan 23, 2019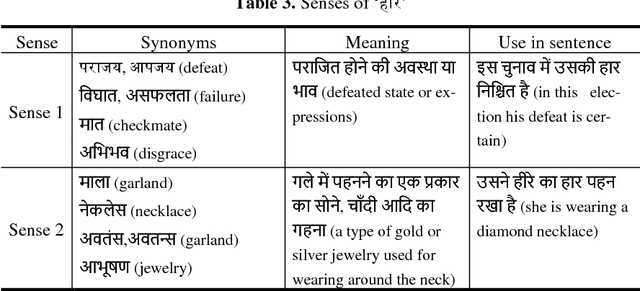
A word having multiple senses in a text introduces the lexical semantic task to find out which particular sense is appropriate for the given context. One such task is Word sense disambiguation which refers to the identification of the most appropriate meaning of the polysemous word in a given context using computational algorithms. The language processing research in Hindi, the official language of India, and other Indian languages is restricted by unavailability of the standard corpus. For Hindi word sense disambiguation also, the large corpus is not available. In this work, we prepared the text containing new senses of certain words leading to the enrichment of the sense-tagged Hindi corpus of sixty polysemous words. Furthermore, we analyzed two novel lexical associations for Hindi word sense disambiguation based on the contextual features of the polysemous word. The evaluation of these methods is carried out over learning algorithms and favorable results are achieved.