 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColoring Deep CNN Layers with Activation Hue Loss
Oct 05, 2023This paper proposes a novel hue-like angular parameter to model the structure of deep convolutional neural network (CNN) activation space, referred to as the {\em activation hue}, for the purpose of regularizing models for more effective learning. The activation hue generalizes the notion of color hue angle in standard 3-channel RGB intensity space to $N$-channel activation space. A series of observations based on nearest neighbor indexing of activation vectors with pre-trained networks indicate that class-informative activations are concentrated about an angle $\theta$ in both the $(x,y)$ image plane and in multi-channel activation space. A regularization term in the form of hue-like angular $\theta$ labels is proposed to complement standard one-hot loss. Training from scratch using combined one-hot + activation hue loss improves classification performance modestly for a wide variety of classification tasks, including ImageNet.
U Symmetry-breaking Observed in Generic CNN Bottleneck Layers
Jun 05, 2022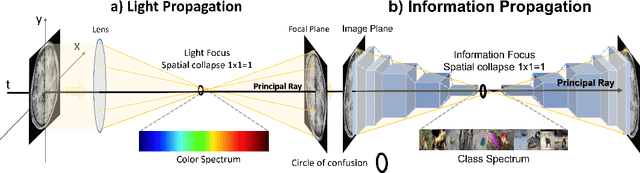

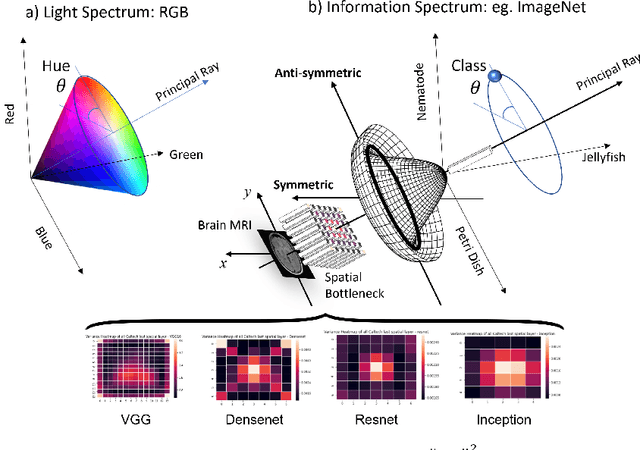
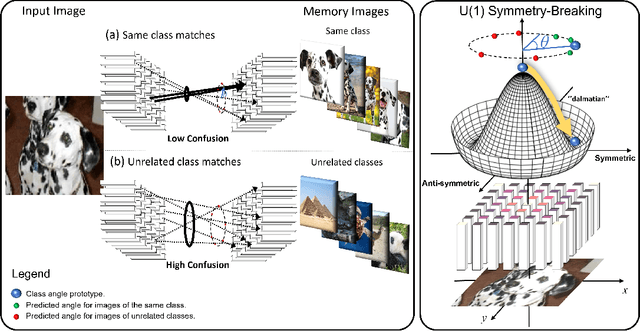
We report on a significant discovery linking deep convolutional neural networks (CNN) to biological vision and fundamental particle physics. A model of information propagation in a CNN is proposed via an analogy to an optical system, where bosonic particles (i.e. photons) are concentrated as the 2D spatial resolution of the image collapses to a focal point $1\times 1=1$. A 3D space $(x,y,t)$ is defined by $(x,y)$ coordinates in the image plane and CNN layer $t$, where a principal ray $(0,0,t)$ runs in the direction of information propagation through both the optical axis and the image center pixel located at $(x,y)=(0,0)$, about which the sharpest possible spatial focus is limited to a circle of confusion in the image plane. Our novel insight is to model the principal optical ray $(0,0,t)$ as geometrically equivalent to the medial vector in the positive orthant $I(x,y) \in R^{N+}$ of a $N$-channel activation space, e.g. along the greyscale (or luminance) vector $(t,t,t)$ in $RGB$ colour space. Information is thus concentrated into an energy potential $E(x,y,t)=\|I(x,y,t)\|^2$, which, particularly for bottleneck layers $t$ of generic CNNs, is highly concentrated and symmetric about the spatial origin $(0,0,t)$ and exhibits the well-known "Sombrero" potential of the boson particle. This symmetry is broken in classification, where bottleneck layers of generic pre-trained CNN models exhibit a consistent class-specific bias towards an angle $\theta \in U(1)$ defined simultaneously in the image plane and in activation feature space. Initial observations validate our hypothesis from generic pre-trained CNN activation maps and a bare-bones memory-based classification scheme, with no training or tuning. Training from scratch using a random $U(1)$ class label the leads to improved classification in all cases.