 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompute the edge p-Laplacian centrality for air traffic network
Dec 13, 2025The problem that we would like to solve in this paper is to compute the edge p-Laplacian centrality for the air traffic network. In this problem, instead of computing the edge p-Laplacian centrality directly which is the very hard problem, we convert the air traffic network to the line graph. Finally, we will compute the node p-Laplacian centrality of the line graph which is equivalent to the edge p-Laplacian of the air traffic network. In this paper, the novel un-normalized graph (p-) Laplacian based ranking method will be developed based on the un-normalized graph p-Laplacian operator definitions such as the curvature operator of graph (i.e. the un-normalized graph 1-Laplacian operator) and will be used to compute the node p-Laplacian centrality of the line graph. The results from the experiments show that the un-normalized graph p-Laplacian ranking methods can be implemented successfully.
Novel sparse PCA method via Runge Kutta numerical method(s) for face recognition
Mar 30, 2025
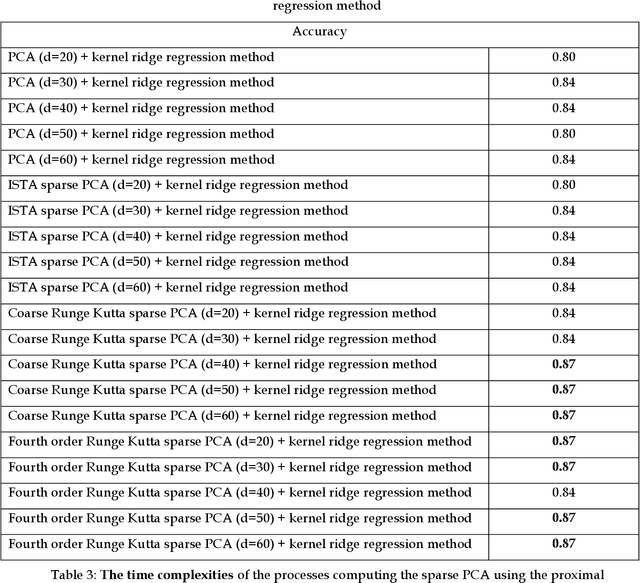
Face recognition is a crucial topic in data science and biometric security, with applications spanning military, finance, and retail industries. This paper explores the implementation of sparse Principal Component Analysis (PCA) using the Proximal Gradient method (also known as ISTA) and the Runge-Kutta numerical methods. To address the face recognition problem, we integrate sparse PCA with either the k-nearest neighbor method or the kernel ridge regression method. Experimental results demonstrate that combining sparse PCA-solved via the Proximal Gradient method or the Runge-Kutta numerical approach-with a classification system yields higher accuracy compared to standard PCA. Additionally, we observe that the Runge-Kutta-based sparse PCA computation consistently outperforms the Proximal Gradient method in terms of speed.
Solve sparse PCA problem by employing Hamiltonian system and leapfrog method
Mar 30, 2025
Principal Component Analysis (PCA) is a widely utilized technique for dimensionality reduction; however, its inherent lack of interpretability-stemming from dense linear combinations of all feature-limits its applicability in many domains. In this paper, we propose a novel sparse PCA algorithm that imposes sparsity through a smooth L1 penalty and leverages a Hamiltonian formulation solved via geometric integration techniques. Specifically, we implement two distinct numerical methods-one based on the Proximal Gradient (ISTA) approach and another employing a leapfrog (fourth-order Runge-Kutta) scheme-to minimize the energy function that balances variance maximization with sparsity enforcement. To extract a subset of sparse principal components, we further incorporate a deflation technique and subsequently transform the original high-dimensional face data into a lower-dimensional feature space. Experimental evaluations on a face recognition dataset-using both k-nearest neighbor and kernel ridge regression classifiers-demonstrate that the proposed sparse PCA methods consistently achieve higher classification accuracy than conventional PCA. Future research will extend this framework to integrate sparse PCA with modern deep learning architectures for multimodal recognition tasks.
Hypergraph Laplacian Eigenmaps and Face Recognition Problems
May 27, 2024

Face recognition is a very important topic in data science and biometric security research areas. It has multiple applications in military, finance, and retail, to name a few. In this paper, the novel hypergraph Laplacian Eigenmaps will be proposed and combine with the k nearest-neighbor method and/or with the kernel ridge regression method to solve the face recognition problem. Experimental results illustrate that the accuracy of the combination of the novel hypergraph Laplacian Eigenmaps and one specific classification system is similar to the accuracy of the combination of the old symmetric normalized hypergraph Laplacian Eigenmaps method and one specific classification system.
Improved sparse PCA method for face and image recognition
Dec 01, 2021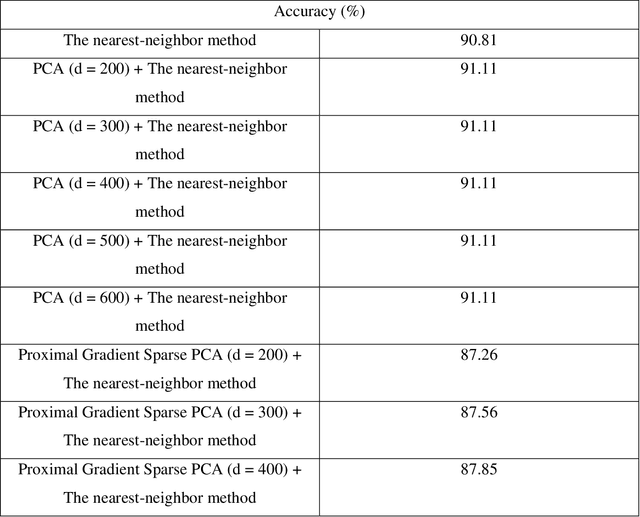
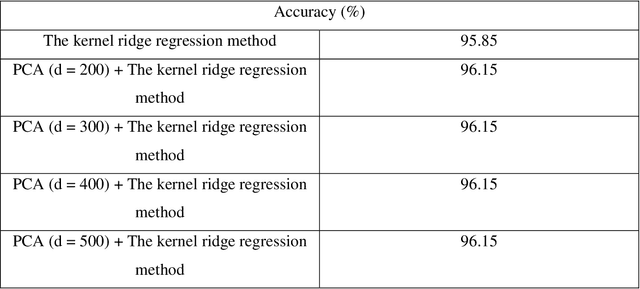

Face recognition is the very significant field in pattern recognition area. It has multiple applications in military and finance, to name a few. In this paper, the combination of the sparse PCA with the nearest-neighbor method (and with the kernel ridge regression method) will be proposed and will be applied to solve the face recognition problem. Experimental results illustrate that the accuracy of the combination of the sparse PCA method (using the proximal gradient method and the FISTA method) and one specific classification system may be lower than the accuracy of the combination of the PCA method and one specific classification system but sometimes the combination of the sparse PCA method (using the proximal gradient method or the FISTA method) and one specific classification system leads to better accuracy. Moreover, we recognize that the process computing the sparse PCA algorithm using the FISTA method is always faster than the process computing the sparse PCA algorithm using the proximal gradient method.
Text classification problems via BERT embedding method and graph convolutional neural network
Nov 30, 2021
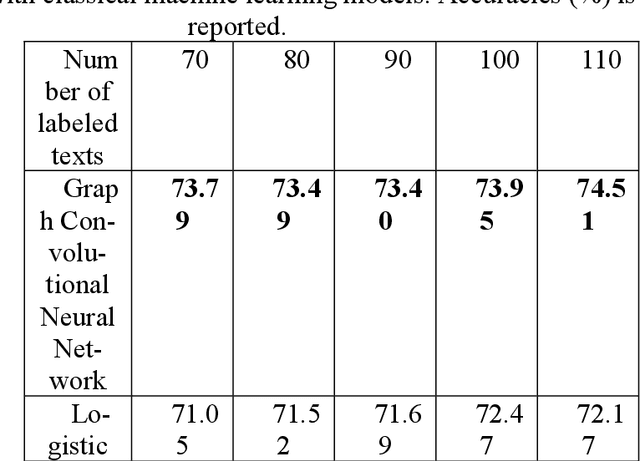
This paper presents the novel way combining the BERT embedding method and the graph convolutional neural network. This combination is employed to solve the text classification problem. Initially, we apply the BERT embedding method to the texts (in the BBC news dataset and the IMDB movie reviews dataset) in order to transform all the texts to numerical vector. Then, the graph convolutional neural network will be applied to these numerical vectors to classify these texts into their ap-propriate classes/labels. Experiments show that the performance of the graph convolutional neural network model is better than the perfor-mances of the combination of the BERT embedding method with clas-sical machine learning models.
Directed hypergraph neural network
Aug 09, 2020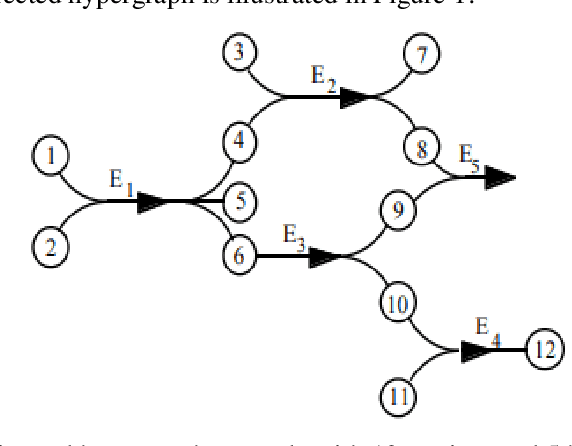
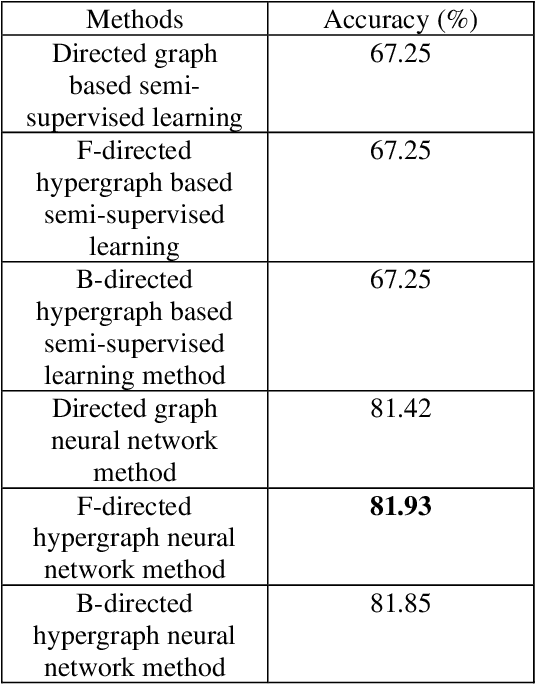

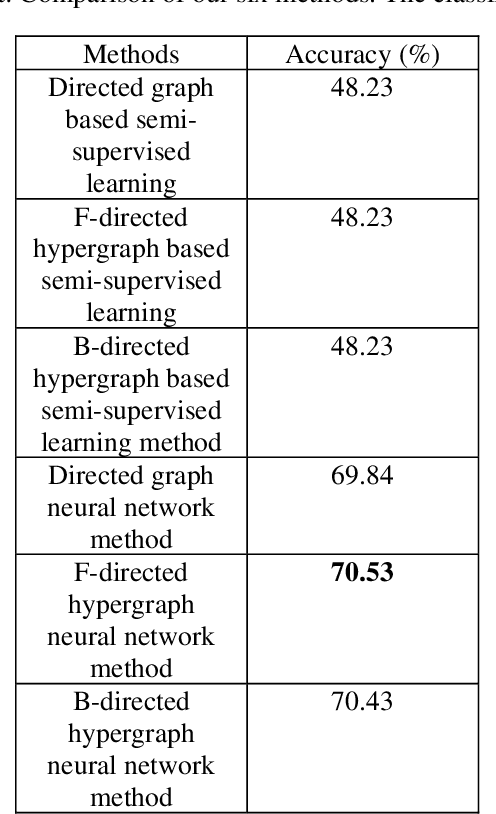
To deal with irregular data structure, graph convolution neural networks have been developed by a lot of data scientists. However, data scientists just have concentrated primarily on developing deep neural network method for un-directed graph. In this paper, we will present the novel neural network method for directed hypergraph. In the other words, we will develop not only the novel directed hypergraph neural network method but also the novel directed hypergraph based semi-supervised learning method. These methods are employed to solve the node classification task. The two datasets that are used in the experiments are the cora and the citeseer datasets. Among the classic directed graph based semi-supervised learning method, the novel directed hypergraph based semi-supervised learning method, the novel directed hypergraph neural network method that are utilized to solve this node classification task, we recognize that the novel directed hypergraph neural network achieves the highest accuracies.
Tensor Sparse PCA and Face Recognition: A Novel Approach
Apr 12, 2019
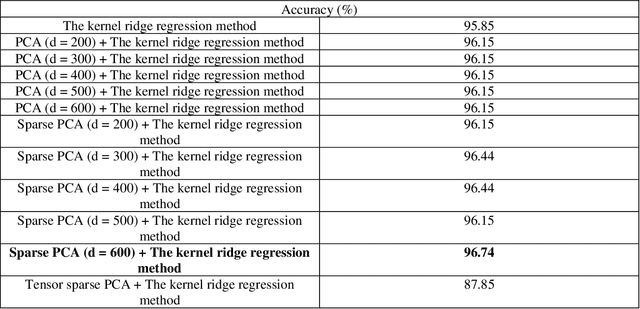
Face recognition is the important field in machine learning and pattern recognition research area. It has a lot of applications in military, finance, public security, to name a few. In this paper, the combination of the tensor sparse PCA with the nearest-neighbor method (and with the kernel ridge regression method) will be proposed and applied to the face dataset. Experimental results show that the combination of the tensor sparse PCA with any classification system does not always reach the best accuracy performance measures. However, the accuracy of the combination of the sparse PCA method and one specific classification system is always better than the accuracy of the combination of the PCA method and one specific classification system and is always better than the accuracy of the classification system itself.
Un-normalized hypergraph p-Laplacian based semi-supervised learning methods
Nov 06, 2018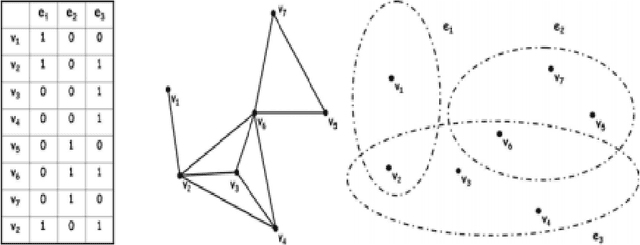
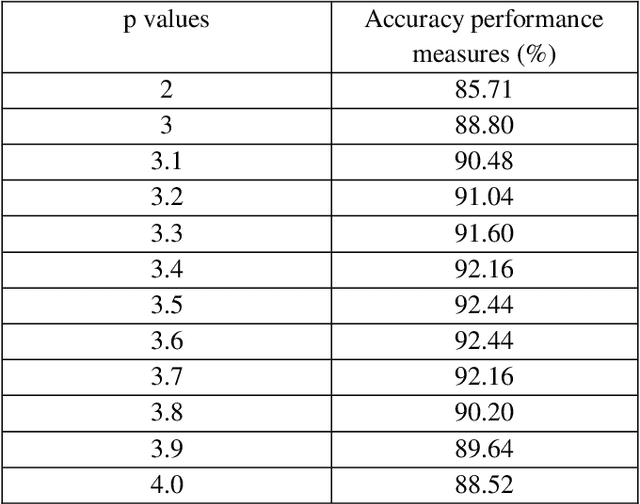
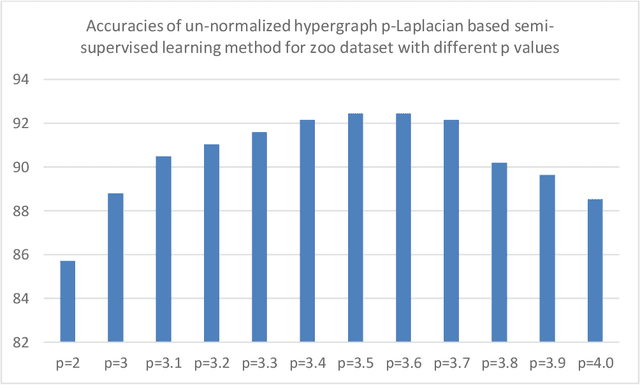
Most network-based machine learning methods assume that the labels of two adjacent samples in the network are likely to be the same. However, assuming the pairwise relationship between samples is not complete. The information a group of samples that shows very similar pattern and tends to have similar labels is missed. The natural way overcoming the information loss of the above assumption is to represent the feature dataset of samples as the hypergraph. Thus, in this paper, we will present the un-normalized hypergraph p-Laplacian semi-supervised learning methods. These methods will be applied to the zoo dataset and the tiny version of 20 newsgroups dataset. Experiment results show that the accuracy performance measures of these un-normalized hypergraph p-Laplacian based semi-supervised learning methods are significantly greater than the accuracy performance measure of the un-normalized hypergraph Laplacian based semi-supervised learning method (the current state of the art method hypergraph Laplacian based semi-supervised learning method for classification problem with p=2).
Hypergraph based semi-supervised learning algorithms applied to speech recognition problem: a novel approach
Oct 28, 2018

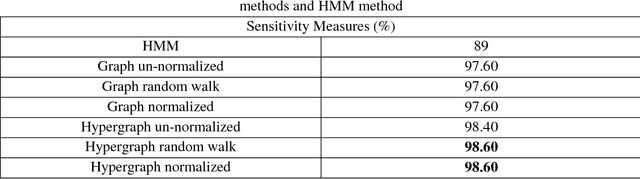
Most network-based speech recognition methods are based on the assumption that the labels of two adjacent speech samples in the network are likely to be the same. However, assuming the pairwise relationship between speech samples is not complete. The information a group of speech samples that show very similar patterns and tend to have similar labels is missed. The natural way overcoming the information loss of the above assumption is to represent the feature data of speech samples as the hypergraph. Thus, in this paper, the three un-normalized, random walk, and symmetric normalized hypergraph Laplacian based semi-supervised learning methods applied to hypergraph constructed from the feature data of speech samples in order to predict the labels of speech samples are introduced. Experiment results show that the sensitivity performance measures of these three hypergraph Laplacian based semi-supervised learning methods are greater than the sensitivity performance measures of the Hidden Markov Model method (the current state of the art method applied to speech recognition problem) and graph based semi-supervised learning methods (i.e. the current state of the art network-based method for classification problems) applied to network created from the feature data of speech samples.