 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypergraph based semi-supervised learning algorithms applied to speech recognition problem: a novel approach
Paper and Code
Oct 28, 2018

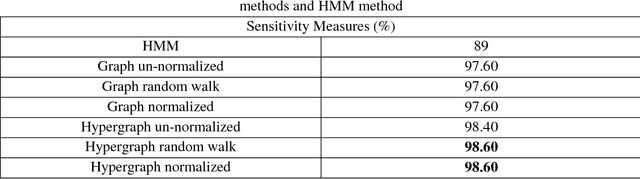
Most network-based speech recognition methods are based on the assumption that the labels of two adjacent speech samples in the network are likely to be the same. However, assuming the pairwise relationship between speech samples is not complete. The information a group of speech samples that show very similar patterns and tend to have similar labels is missed. The natural way overcoming the information loss of the above assumption is to represent the feature data of speech samples as the hypergraph. Thus, in this paper, the three un-normalized, random walk, and symmetric normalized hypergraph Laplacian based semi-supervised learning methods applied to hypergraph constructed from the feature data of speech samples in order to predict the labels of speech samples are introduced. Experiment results show that the sensitivity performance measures of these three hypergraph Laplacian based semi-supervised learning methods are greater than the sensitivity performance measures of the Hidden Markov Model method (the current state of the art method applied to speech recognition problem) and graph based semi-supervised learning methods (i.e. the current state of the art network-based method for classification problems) applied to network created from the feature data of speech samples.