 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Kalman Filter Based Framework for Monitoring the Performance of In-Hospital Mortality Prediction Models Over Time
Feb 09, 2024



Unlike in a clinical trial, where researchers get to determine the least number of positive and negative samples required, or in a machine learning study where the size and the class distribution of the validation set is static and known, in a real-world scenario, there is little control over the size and distribution of incoming patients. As a result, when measured during different time periods, evaluation metrics like Area under the Receiver Operating Curve (AUCROC) and Area Under the Precision-Recall Curve(AUCPR) may not be directly comparable. Therefore, in this study, for binary classifiers running in a long time period, we proposed to adjust these performance metrics for sample size and class distribution, so that a fair comparison can be made between two time periods. Note that the number of samples and the class distribution, namely the ratio of positive samples, are two robustness factors which affect the variance of AUCROC. To better estimate the mean of performance metrics and understand the change of performance over time, we propose a Kalman filter based framework with extrapolated variance adjusted for the total number of samples and the number of positive samples during different time periods. The efficacy of this method is demonstrated first on a synthetic dataset and then retrospectively applied to a 2-days ahead in-hospital mortality prediction model for COVID-19 patients during 2021 and 2022. Further, we conclude that our prediction model is not significantly affected by the evolution of the disease, improved treatments and changes in hospital operational plans.
Continual Deterioration Prediction for Hospitalized COVID-19 Patients
Jan 19, 2021
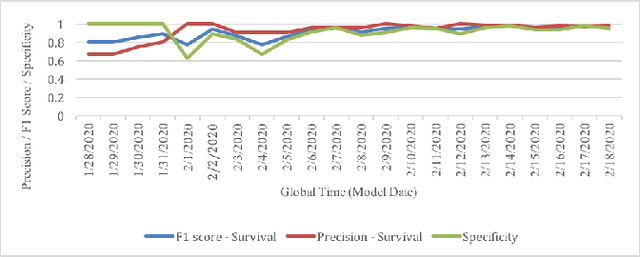
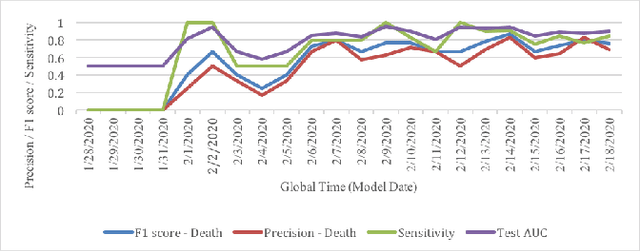

Leading up to August 2020, COVID-19 has spread to almost every country in the world, causing millions of infected and hundreds of thousands of deaths. In this paper, we first verify the assumption that clinical variables could have time-varying effects on COVID-19 outcomes. Then, we develop a temporal stratification approach to make daily predictions on patients' outcome at the end of hospital stay. Training data is segmented by the remaining length of stay, which is a proxy for the patient's overall condition. Based on this, a sequence of predictive models are built, one for each time segment. Thanks to the publicly shared data, we were able to build and evaluate prototype models. Preliminary experiments show 0.98 AUROC, 0.91 F1 score and 0.97 AUPR on continuous deterioration prediction, encouraging further development of the model as well as validations on different datasets. We also verify the key assumption which motivates our method. Clinical variables could have time-varying effects on COVID-19 outcomes. That is to say, the feature importance of a variable in the predictive model varies at different disease stages.