 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartially blind domain adaptation for age prediction from DNA methylation data
Dec 20, 2016
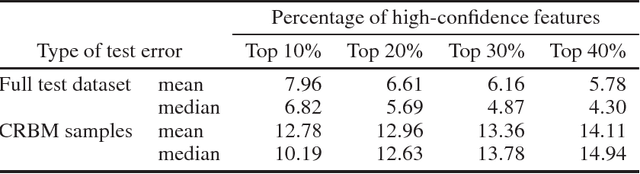
Over the last years, huge resources of biological and medical data have become available for research. This data offers great chances for machine learning applications in health care, e.g. for precision medicine, but is also challenging to analyze. Typical challenges include a large number of possibly correlated features and heterogeneity in the data. One flourishing field of biological research in which this is relevant is epigenetics. Here, especially large amounts of DNA methylation data have emerged. This epigenetic mark has been used to predict a donor's 'epigenetic age' and increased epigenetic aging has been linked to lifestyle and disease history. In this paper we propose an adaptive model which performs feature selection for each test sample individually based on the distribution of the input data. The method can be seen as partially blind domain adaptation. We apply the model to the problem of age prediction based on DNA methylation data from a variety of tissues, and compare it to a standard model, which does not take heterogeneity into account. The standard approach has particularly bad performance on one tissue type on which we show substantial improvement with our new adaptive approach even though no samples of that tissue were part of the training data.