 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Baseline for Beam Search Reranking
Dec 17, 2022Reranking methods in machine translation aim to close the gap between common evaluation metrics (e.g. BLEU) and maximum likelihood learning and decoding algorithms. Prior works address this challenge by training models to rerank beam search candidates according to their predicted BLEU scores, building upon large models pretrained on massive monolingual corpora -- a privilege that was never made available to the baseline translation model. In this work, we examine a simple approach for training rerankers to predict translation candidates' BLEU scores without introducing additional data or parameters. Our approach can be used as a clean baseline, decoupled from external factors, for future research in this area.
Can Latent Alignments Improve Autoregressive Machine Translation?
Apr 19, 2021
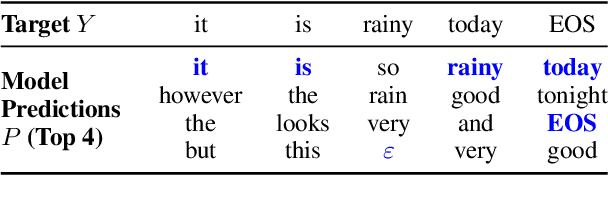
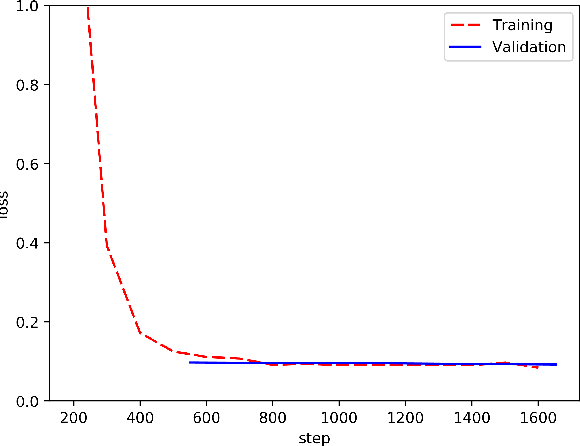

Latent alignment objectives such as CTC and AXE significantly improve non-autoregressive machine translation models. Can they improve autoregressive models as well? We explore the possibility of training autoregressive machine translation models with latent alignment objectives, and observe that, in practice, this approach results in degenerate models. We provide a theoretical explanation for these empirical results, and prove that latent alignment objectives are incompatible with teacher forcing.