 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanEval on Latest GPT Models -- 2024
Feb 20, 2024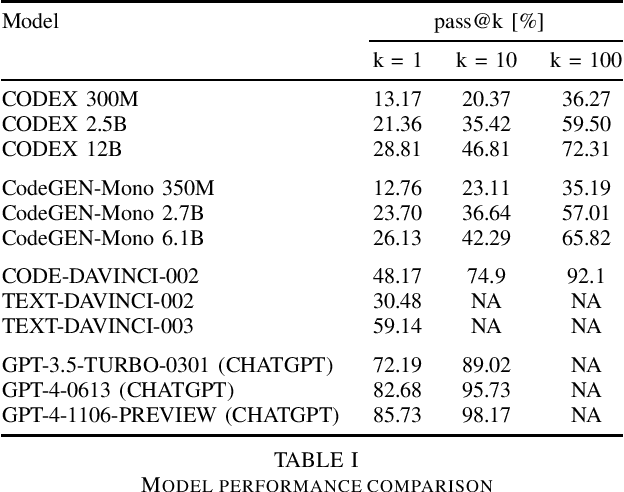
In 2023, we are using the latest models of GPT-4 to advance program synthesis. The large language models have significantly improved the state-of-the-art for this purpose. To make these advancements more accessible, we have created a repository that connects these models to Huamn Eval. This dataset was initally developed to be used with a language model called CODEGEN on natural and programming language data. The utility of these trained models is showcased by demonstrating their competitive performance in zero-shot Python code generation on HumanEval tasks compared to previous state-of-the-art solutions. Additionally, this gives way to developing more multi-step paradigm synthesis. This benchmark features 160 diverse problem sets factorized into multistep prompts that our analysis shows significantly improves program synthesis over single-turn inputs. All code is open source at https://github.com/daniel442li/gpt-human-eval .
Testing LLMs on Code Generation with Varying Levels of Prompt Specificity
Nov 10, 2023Large language models (LLMs) have demonstrated unparalleled prowess in mimicking human-like text generation and processing. Among the myriad of applications that benefit from LLMs, automated code generation is increasingly promising. The potential to transform natural language prompts into executable code promises a major shift in software development practices and paves the way for significant reductions in manual coding efforts and the likelihood of human-induced errors. This paper reports the results of a study that evaluates the performance of various LLMs, such as Bard, ChatGPT-3.5, ChatGPT-4, and Claude-2, in generating Python for coding problems. We focus on how levels of prompt specificity impact the accuracy, time efficiency, and space efficiency of the generated code. A benchmark of 104 coding problems, each with four types of prompts with varying degrees of tests and specificity, was employed to examine these aspects comprehensively. Our results indicate significant variations in performance across different LLMs and prompt types, and its key contribution is to reveal the ideal prompting strategy for creating accurate Python functions. This study lays the groundwork for further research in LLM capabilities and suggests practical implications for utilizing LLMs in automated code generation tasks and test-driven development.