 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumanEval on Latest GPT Models -- 2024
Paper and Code
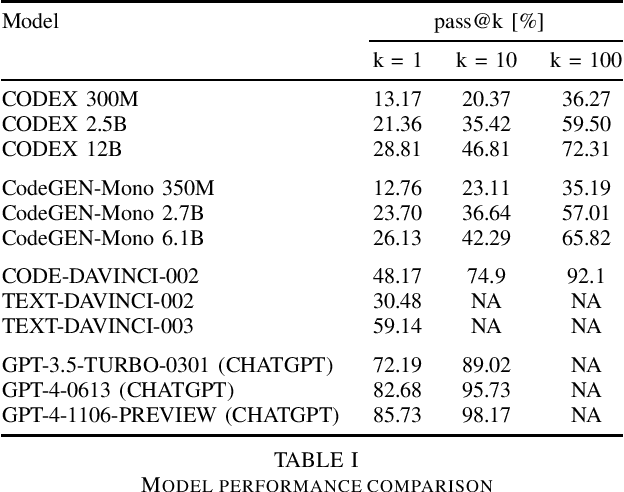
In 2023, we are using the latest models of GPT-4 to advance program synthesis. The large language models have significantly improved the state-of-the-art for this purpose. To make these advancements more accessible, we have created a repository that connects these models to Huamn Eval. This dataset was initally developed to be used with a language model called CODEGEN on natural and programming language data. The utility of these trained models is showcased by demonstrating their competitive performance in zero-shot Python code generation on HumanEval tasks compared to previous state-of-the-art solutions. Additionally, this gives way to developing more multi-step paradigm synthesis. This benchmark features 160 diverse problem sets factorized into multistep prompts that our analysis shows significantly improves program synthesis over single-turn inputs. All code is open source at https://github.com/daniel442li/gpt-human-eval .