 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZETAR: Modeling and Computational Design of Strategic and Adaptive Compliance Policies
Apr 05, 2022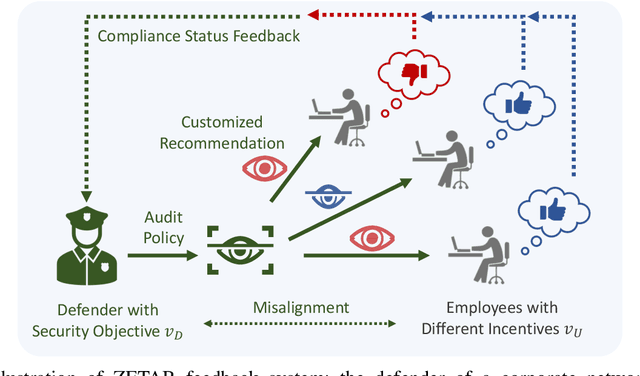
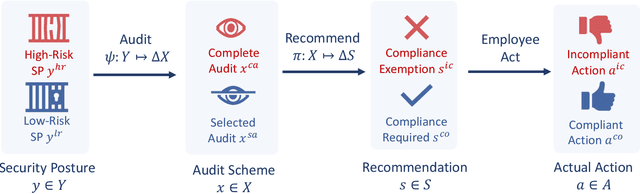
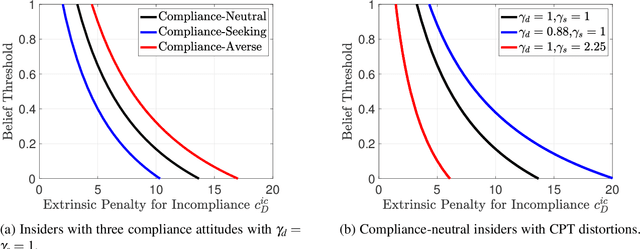
Security compliance management plays an important role in mitigating insider threats. Incentive design is a proactive and non-invasive approach to achieving compliance by aligning an employee's incentive with the defender's security objective. Controlling insiders' incentives to elicit proper actions is challenging because they are neither precisely known nor directly controllable. To this end, we develop ZETAR, a zero-trust audit and recommendation framework, to provide a quantitative approach to model incentives of the insiders and design customized and strategic recommendation policies to improve their compliance. We formulate primal and dual convex programs to compute the optimal bespoke recommendation policies. We create a theoretical underpinning for understanding trust and compliance, and it leads to security insights, including fundamental limits of Completely Trustworthy (CT) recommendation, the principle of compliance equivalency, and strategic information disclosure. This work proposes finite-step algorithms to efficiently learn the CT policy set when employees' incentives are unknown. Finally, we present a case study to corroborate the design and illustrate a formal way to achieve compliance for insiders with different risk attitudes. Our results show that the optimal recommendation policy leads to a significant improvement in compliance for risk-averse insiders. Moreover, CT recommendation policies promote insiders' satisfaction.
RADAMS: Resilient and Adaptive Alert and Attention Management Strategy against Informational Denial-of-Service (IDoS) Attacks
Nov 01, 2021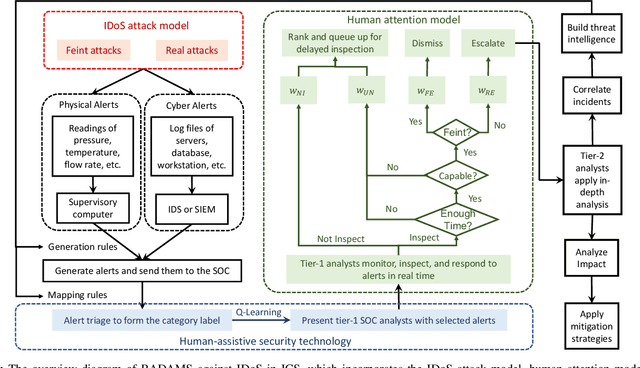

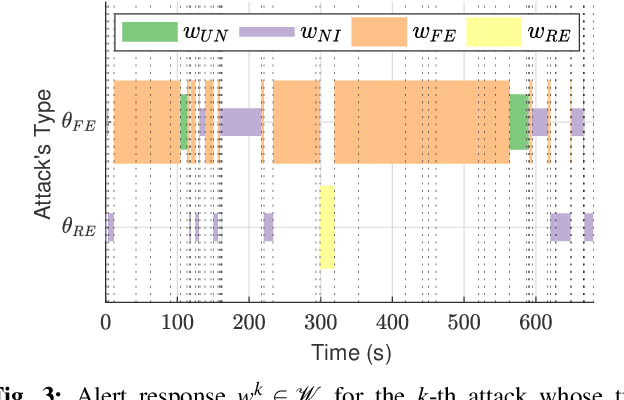
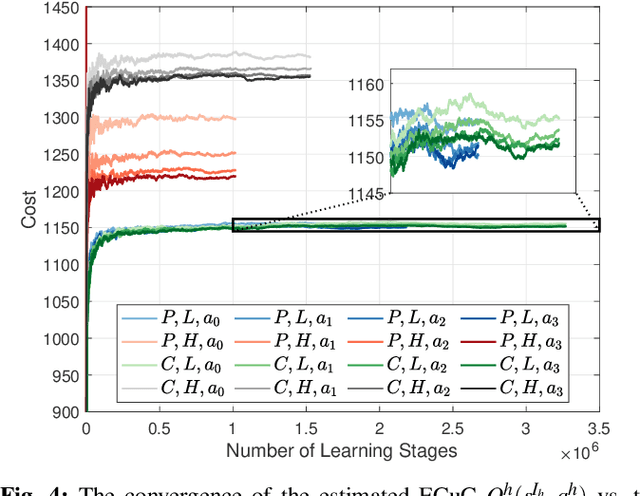
Attacks exploiting human attentional vulnerability have posed severe threats to cybersecurity. In this work, we identify and formally define a new type of proactive attentional attacks called Informational Denial-of-Service (IDoS) attacks that generate a large volume of feint attacks to overload human operators and hide real attacks among feints. We incorporate human factors (e.g., levels of expertise, stress, and efficiency) and empirical results (e.g., the Yerkes-Dodson law and the sunk cost fallacy) to model the operators' attention dynamics and their decision-making processes along with the real-time alert monitoring and inspection. To assist human operators in timely and accurately dismissing the feints and escalating the real attacks, we develop a Resilient and Adaptive Data-driven alert and Attention Management Strategy (RADAMS) that de-emphasizes alerts selectively based on the alerts' observable features. RADAMS uses reinforcement learning to achieve a customized and transferable design for various human operators and evolving IDoS attacks. The integrated modeling and theoretical analysis lead to the Product Principle of Attention (PPoA), fundamental limits, and the tradeoff among crucial human and economic factors. Experimental results corroborate that the proposed strategy outperforms the default strategy and can reduce the IDoS risk by as much as 20%. Besides, the strategy is resilient to large variations of costs, attack frequencies, and human attention capacities. We have recognized interesting phenomena such as attentional risk equivalency, attacker's dilemma, and the half-truth optimal attack strategy.
Combating Informational Denial-of-Service (IDoS) Attacks: Modeling and Mitigation of Attentional Human Vulnerability
Aug 04, 2021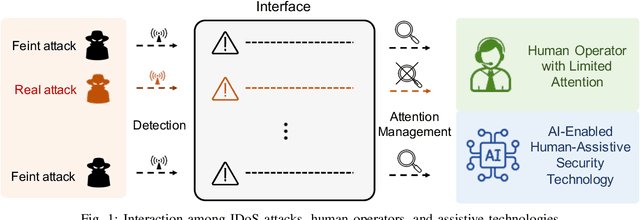
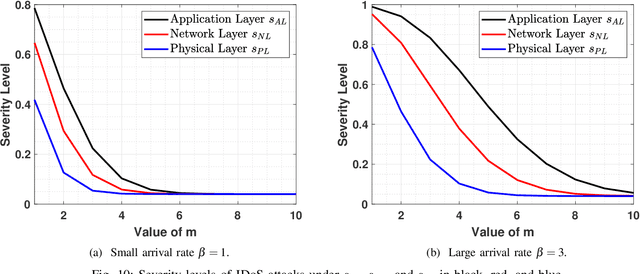
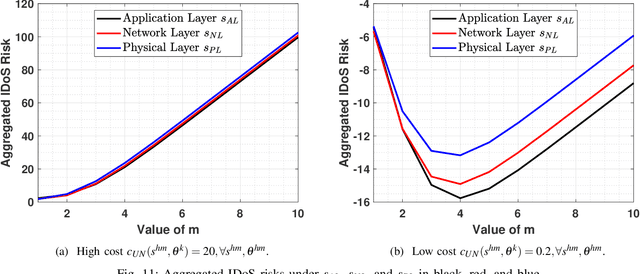
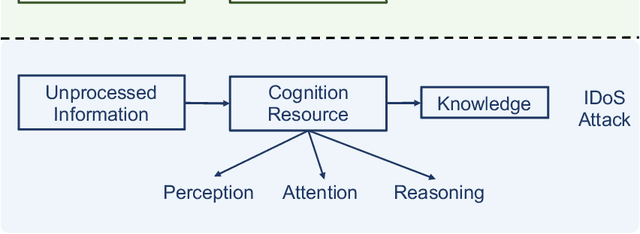
This work proposes a new class of proactive attacks called the Informational Denial-of-Service (IDoS) attacks that exploit the attentional human vulnerability. By generating a large volume of feints, IDoS attacks deplete the cognition resources of human operators to prevent humans from identifying the real attacks hidden among feints. This work aims to formally define IDoS attacks, quantify their consequences, and develop human-assistive security technologies to mitigate the severity level and risks of IDoS attacks. To this end, we model the feint and real attacks' sequential arrivals with category labels as a semi-Markov process. The assistive technology strategically manages human attention by highlighting selective alerts periodically to prevent the distraction of other alerts. A data-driven approach is applied to evaluate human performance under different Attention Management (AM) strategies. Under a representative special case, we establish the computational equivalency between two dynamic programming representations to simplify the theoretical computation and the online learning. A case study corroborates the effectiveness of the learning framework. The numerical results illustrate how AM strategies can alleviate the severity level and the risk of IDoS attacks. Furthermore, we characterize the fundamental limits of the minimum severity level under all AM strategies and the maximum length of the inspection period to reduce the IDoS risks.
Reinforcement Learning for Feedback-Enabled Cyber Resilience
Jul 02, 2021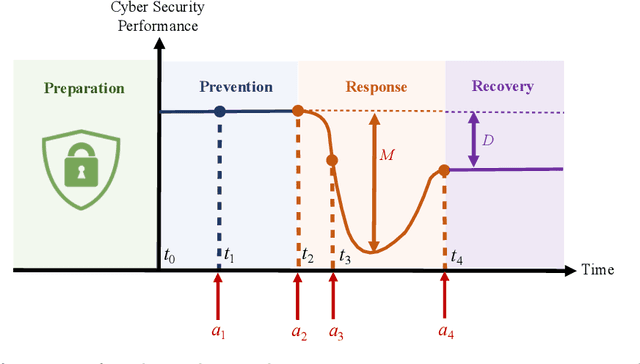
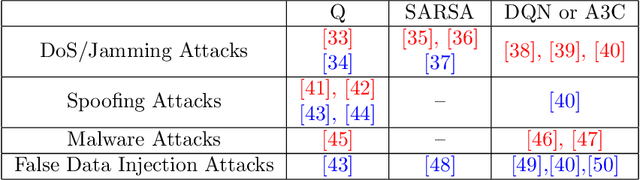
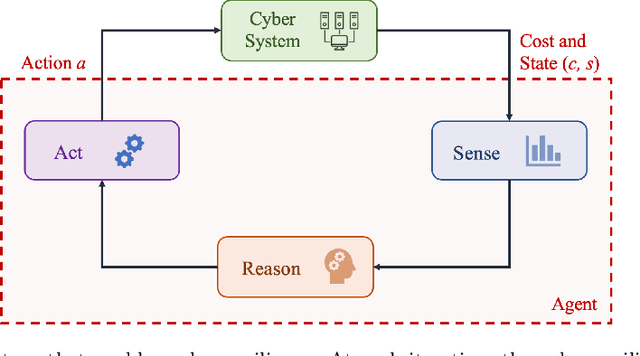

The rapid growth in the number of devices and their connectivity has enlarged the attack surface and weakened cyber systems. As attackers become increasingly sophisticated and resourceful, mere reliance on traditional cyber protection, such as intrusion detection, firewalls, and encryption, is insufficient to secure cyber systems. Cyber resilience provides a new security paradigm that complements inadequate protection with resilience mechanisms. A Cyber-Resilient Mechanism (CRM) adapts to the known or zero-day threats and uncertainties in real-time and strategically responds to them to maintain the critical functions of the cyber systems. Feedback architectures play a pivotal role in enabling the online sensing, reasoning, and actuation of the CRM. Reinforcement Learning (RL) is an important class of algorithms that epitomize the feedback architectures for cyber resiliency, allowing the CRM to provide dynamic and sequential responses to attacks with limited prior knowledge of the attacker. In this work, we review the literature on RL for cyber resiliency and discuss the cyber-resilient defenses against three major types of vulnerabilities, i.e., posture-related, information-related, and human-related vulnerabilities. We introduce moving target defense, defensive cyber deception, and assistive human security technologies as three application domains of CRMs to elaborate on their designs. The RL technique also has vulnerabilities itself. We explain the major vulnerabilities of RL and present several attack models in which the attacks target the rewards, the measurements, and the actuators. We show that the attacker can trick the RL agent into learning a nefarious policy with minimum attacking effort, which shows serious security concerns for RL-enabled systems. Finally, we discuss the future challenges of RL for cyber security and resiliency and emerging applications of RL-based CRMs.
INADVERT: An Interactive and Adaptive Counterdeception Platform for Attention Enhancement and Phishing Prevention
Jun 13, 2021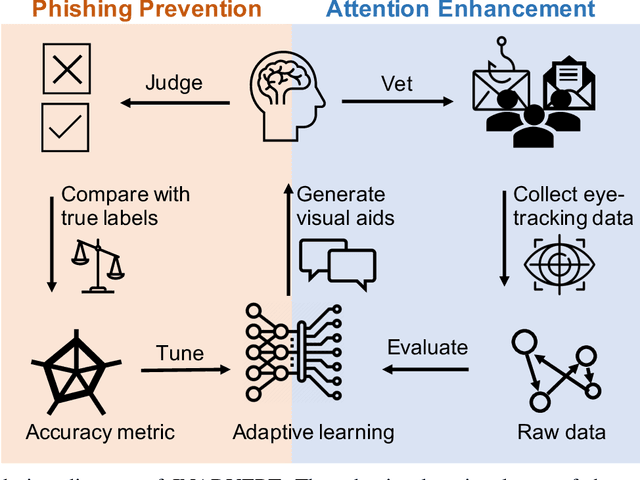

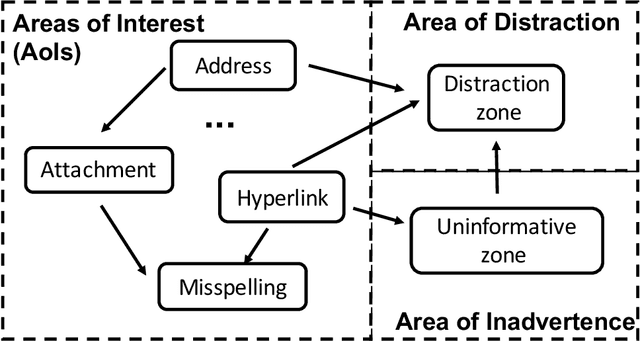
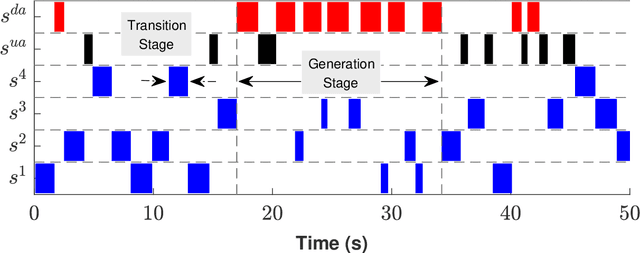
Deceptive attacks exploiting the innate and the acquired vulnerabilities of human users have posed severe threats to information and infrastructure security. This work proposes INADVERT, a systematic solution that generates interactive visual aids in real-time to prevent users from inadvertence and counter visual-deception attacks. Based on the eye-tracking outcomes and proper data compression, the INADVERT platform automatically adapts the visual aids to the user's varying attention status captured by the gaze location and duration. We extract system-level metrics to evaluate the user's average attention level and characterize the magnitude and frequency of the user's mind-wandering behaviors. These metrics contribute to an adaptive enhancement of the user's attention through reinforcement learning. To determine the optimal hyper-parameters in the attention enhancement mechanism, we develop an algorithm based on Bayesian optimization to efficiently update the design of the INADVERT platform and maximize the accuracy of the users' phishing recognition.
Adaptive Honeypot Engagement through Reinforcement Learning of Semi-Markov Decision Processes
Jun 27, 2019

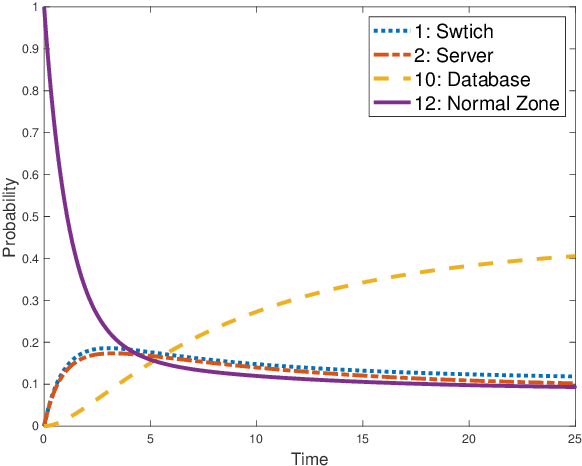
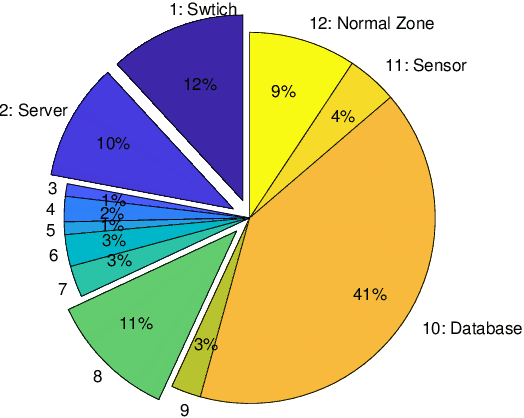
The honeynet is a promising active cyber defense mechanism. It reveals the fundamental Indicators of Compromise (IoC) by luring attackers to conduct adversarial behaviors in a controlled and monitored environment. The active interaction at the honeynet brings a high reward but also introduces high implementation costs and risks of adversarial honeynet exploitation. In this work, we apply the infinite-horizon Semi-Markov Decision Process (SMDP) to characterize the stochastic transition and sojourn time of attackers in the honeynet and quantify the reward-risk trade-off. In particular, we produce adaptive long-term engagement policies shown to be risk-averse, cost-effective, and time-efficient. Numerical results have demonstrated that our adaptive interaction policies can quickly attract attackers to the target honeypot and engage them for a sufficiently long period to obtain worthy threat information. Meanwhile, the penetration probability is kept at a low level. The results show that the expected utility is robust against attackers of a large range of persistence and intelligence. Finally, we apply reinforcement learning to SMDP to solve the curse of modeling. Under a prudent choice of the learning rate and exploration policy, we achieve a quick and robust convergence of the optimal policy and value.