 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating LLMs for Text-to-SQL Generation With Complex SQL Workload
Jul 28, 2024This study presents a comparative analysis of the a complex SQL benchmark, TPC-DS, with two existing text-to-SQL benchmarks, BIRD and Spider. Our findings reveal that TPC-DS queries exhibit a significantly higher level of structural complexity compared to the other two benchmarks. This underscores the need for more intricate benchmarks to simulate realistic scenarios effectively. To facilitate this comparison, we devised several measures of structural complexity and applied them across all three benchmarks. The results of this study can guide future research in the development of more sophisticated text-to-SQL benchmarks. We utilized 11 distinct Language Models (LLMs) to generate SQL queries based on the query descriptions provided by the TPC-DS benchmark. The prompt engineering process incorporated both the query description as outlined in the TPC-DS specification and the database schema of TPC-DS. Our findings indicate that the current state-of-the-art generative AI models fall short in generating accurate decision-making queries. We conducted a comparison of the generated queries with the TPC-DS gold standard queries using a series of fuzzy structure matching techniques based on query features. The results demonstrated that the accuracy of the generated queries is insufficient for practical real-world application.
Incremental Information Gain Mining Of Temporal Relational Streams
Jun 11, 2022
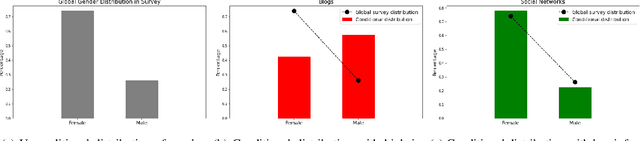
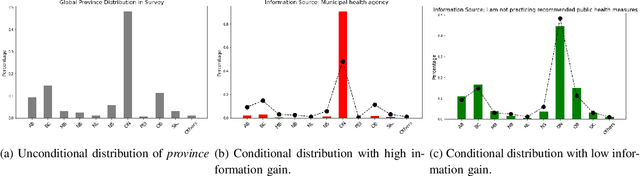

This paper studies the problem of mining for data values with high information gain in relational tables. High information gain can help data analysts and secondary data mining algorithms gain insights into strong statistical dependencies and causality relationship between key metrics. In this paper, we will study the problem of high information gain identification for scenarios involving temporal relations where new records are added continuously to the relations. We show that information gain can be efficiently maintained in an incremental fashion, making it possible to monitor continuously high information gain values.