Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Information Gain Mining Of Temporal Relational Streams
Paper and Code
Jun 11, 2022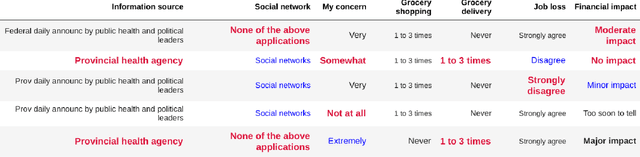
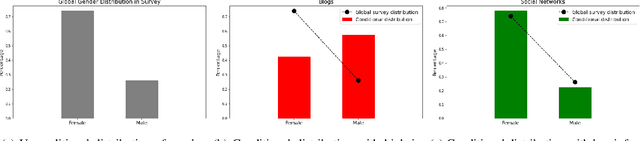
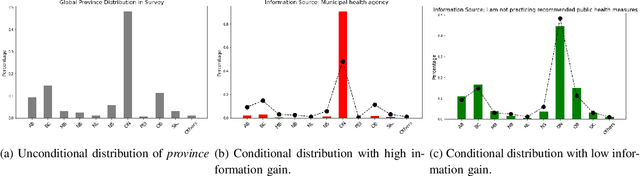

This paper studies the problem of mining for data values with high information gain in relational tables. High information gain can help data analysts and secondary data mining algorithms gain insights into strong statistical dependencies and causality relationship between key metrics. In this paper, we will study the problem of high information gain identification for scenarios involving temporal relations where new records are added continuously to the relations. We show that information gain can be efficiently maintained in an incremental fashion, making it possible to monitor continuously high information gain values.
View paper on