 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGDR: Semantic-guided Disentangled Representation for Unsupervised Cross-modality Medical Image Segmentation
Mar 26, 2022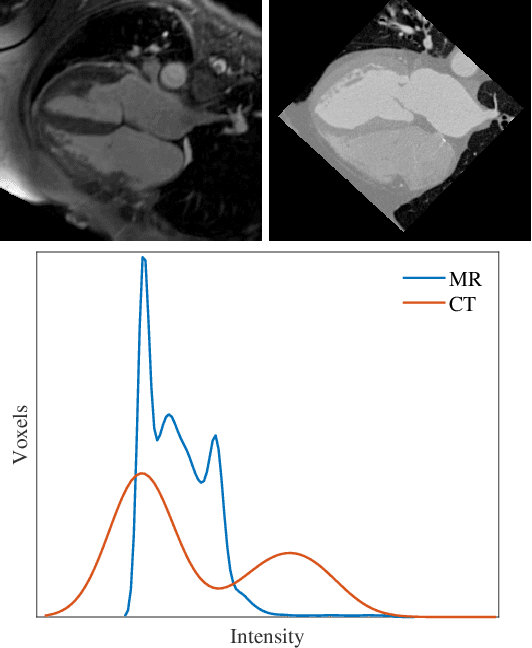
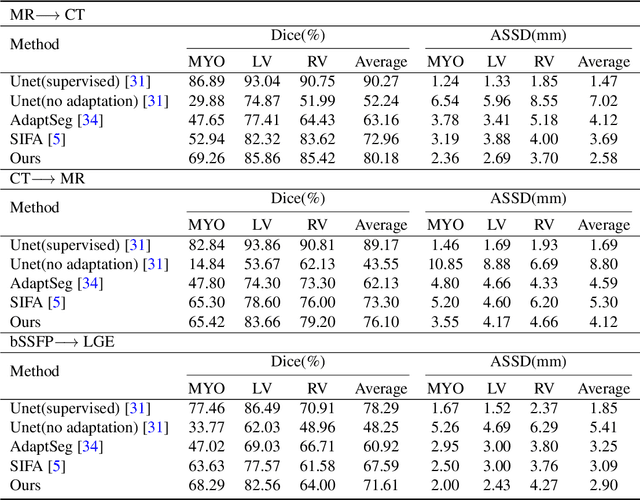
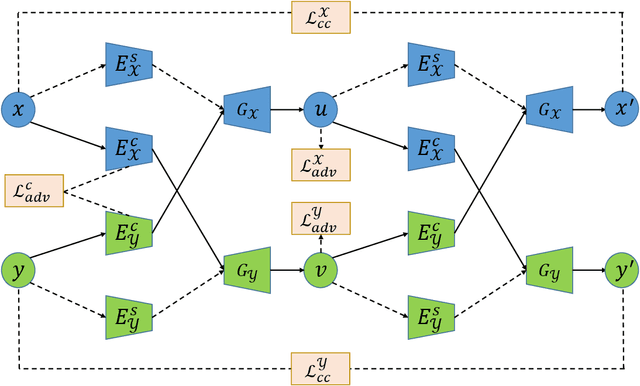

Disentangled representation is a powerful technique to tackle domain shift problem in medical image analysis in unsupervised domain adaptation setting.However, previous methods only focus on exacting domain-invariant feature and ignore whether exacted feature is meaningful for downstream tasks.We propose a novel framework, called semantic-guided disentangled representation (SGDR), an effective method to exact semantically meaningful feature for segmentation task to improve performance of cross modality medical image segmentation in unsupervised domain adaptation setting.To exact the meaningful domain-invariant features of different modality, we introduce a content discriminator to force the content representation to be embedded to the same space and a feature discriminator to exact the meaningful representation.We also use pixel-level annotations to guide the encoder to learn features that are meaningful for segmentation task.We validated our method on two public datasets and experiment results show that our approach outperforms the state of the art methods on two evaluation metrics by a significant margin.
Auto-weighting for Breast Cancer Classification in Multimodal Ultrasound
Aug 08, 2020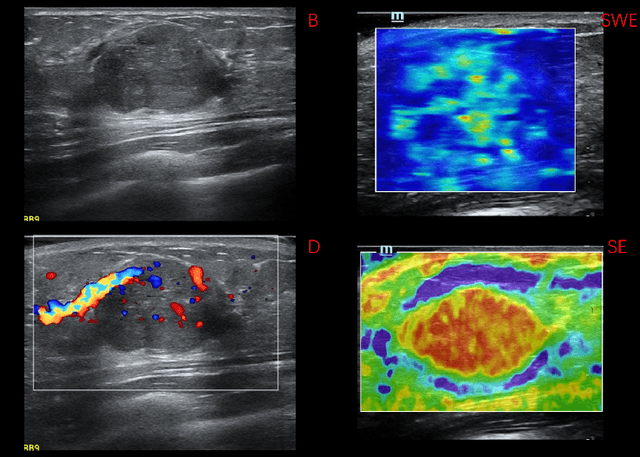
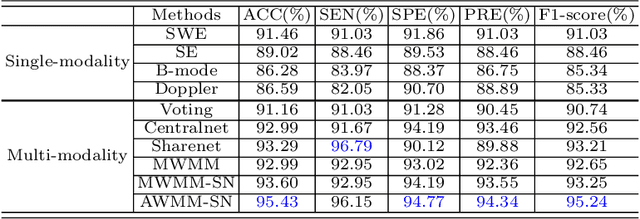
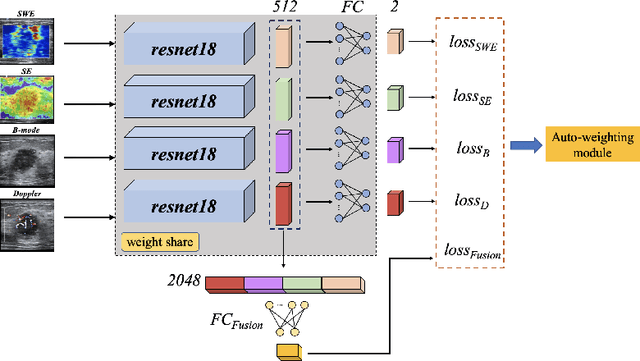
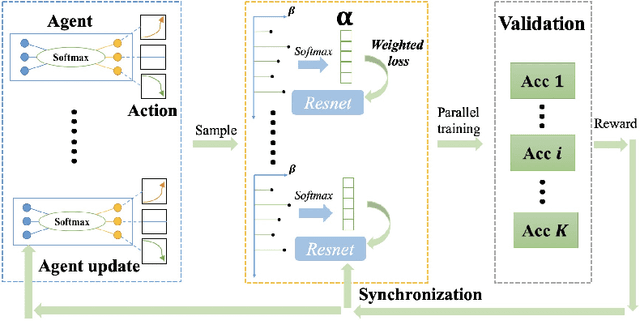
Breast cancer is the most common invasive cancer in women. Besides the primary B-mode ultrasound screening, sonographers have explored the inclusion of Doppler, strain and shear-wave elasticity imaging to advance the diagnosis. However, recognizing useful patterns in all types of images and weighing up the significance of each modality can elude less-experienced clinicians. In this paper, we explore, for the first time, an automatic way to combine the four types of ultrasonography to discriminate between benign and malignant breast nodules. A novel multimodal network is proposed, along with promising learnability and simplicity to improve classification accuracy. The key is using a weight-sharing strategy to encourage interactions between modalities and adopting an additional cross-modalities objective to integrate global information. In contrast to hardcoding the weights of each modality in the model, we embed it in a Reinforcement Learning framework to learn this weighting in an end-to-end manner. Thus the model is trained to seek the optimal multimodal combination without handcrafted heuristics. The proposed framework is evaluated on a dataset contains 1616 set of multimodal images. Results showed that the model scored a high classification accuracy of 95.4%, which indicates the efficiency of the proposed method.