 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSGDR: Semantic-guided Disentangled Representation for Unsupervised Cross-modality Medical Image Segmentation
Paper and Code
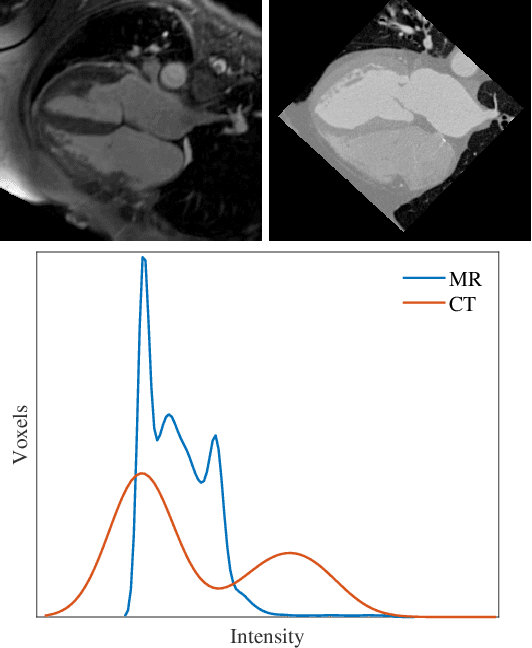
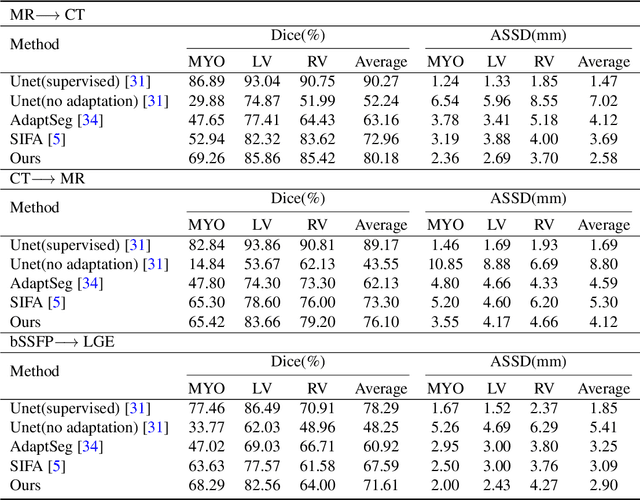
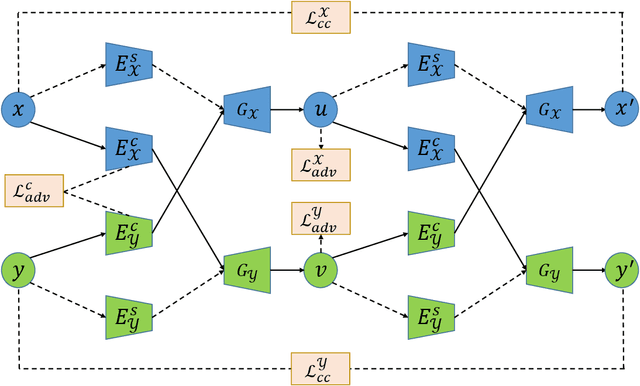

Disentangled representation is a powerful technique to tackle domain shift problem in medical image analysis in unsupervised domain adaptation setting.However, previous methods only focus on exacting domain-invariant feature and ignore whether exacted feature is meaningful for downstream tasks.We propose a novel framework, called semantic-guided disentangled representation (SGDR), an effective method to exact semantically meaningful feature for segmentation task to improve performance of cross modality medical image segmentation in unsupervised domain adaptation setting.To exact the meaningful domain-invariant features of different modality, we introduce a content discriminator to force the content representation to be embedded to the same space and a feature discriminator to exact the meaningful representation.We also use pixel-level annotations to guide the encoder to learn features that are meaningful for segmentation task.We validated our method on two public datasets and experiment results show that our approach outperforms the state of the art methods on two evaluation metrics by a significant margin.