 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reinforcement Learning Method for Environments with Stochastic Variables: Post-Decision Proximal Policy Optimization with Dual Critic Networks
Apr 07, 2025This paper presents Post-Decision Proximal Policy Optimization (PDPPO), a novel variation of the leading deep reinforcement learning method, Proximal Policy Optimization (PPO). The PDPPO state transition process is divided into two steps: a deterministic step resulting in the post-decision state and a stochastic step leading to the next state. Our approach incorporates post-decision states and dual critics to reduce the problem's dimensionality and enhance the accuracy of value function estimation. Lot-sizing is a mixed integer programming problem for which we exemplify such dynamics. The objective of lot-sizing is to optimize production, delivery fulfillment, and inventory levels in uncertain demand and cost parameters. This paper evaluates the performance of PDPPO across various environments and configurations. Notably, PDPPO with a dual critic architecture achieves nearly double the maximum reward of vanilla PPO in specific scenarios, requiring fewer episode iterations and demonstrating faster and more consistent learning across different initializations. On average, PDPPO outperforms PPO in environments with a stochastic component in the state transition. These results support the benefits of using a post-decision state. Integrating this post-decision state in the value function approximation leads to more informed and efficient learning in high-dimensional and stochastic environments.
Solving the optimal stopping problem with reinforcement learning: an application in financial option exercise
Jul 21, 2022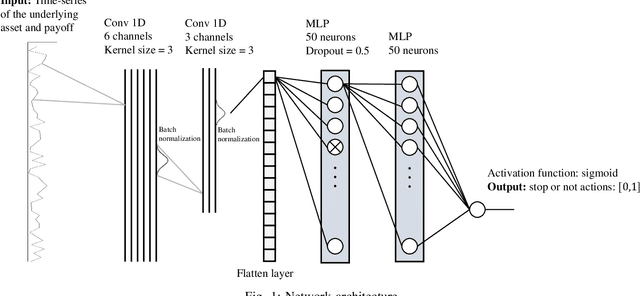

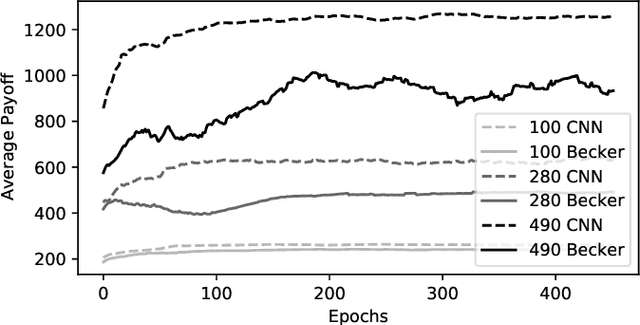

The optimal stopping problem is a category of decision problems with a specific constrained configuration. It is relevant to various real-world applications such as finance and management. To solve the optimal stopping problem, state-of-the-art algorithms in dynamic programming, such as the least-squares Monte Carlo (LSMC), are employed. This type of algorithm relies on path simulations using only the last price of the underlying asset as a state representation. Also, the LSMC was thinking for option valuation where risk-neutral probabilities can be employed to account for uncertainty. However, the general optimal stopping problem goals may not fit the requirements of the LSMC showing auto-correlated prices. We employ a data-driven method that uses Monte Carlo simulation to train and test artificial neural networks (ANN) to solve the optimal stopping problem. Using ANN to solve decision problems is not entirely new. We propose a different architecture that uses convolutional neural networks (CNN) to deal with the dimensionality problem that arises when we transform the whole history of prices into a Markovian state. We present experiments that indicate that our proposed architecture improves results over the previous implementations under specific simulated time series function sets. Lastly, we employ our proposed method to compare the optimal exercise of the financial options problem with the LSMC algorithm. Our experiments show that our method can capture more accurate exercise opportunities when compared to the LSMC. We have outstandingly higher (above 974\% improvement) expected payoff from these exercise policies under the many Monte Carlo simulations that used the real-world return database on the out-of-sample (test) data.
Intelligent Trading Systems: A Sentiment-Aware Reinforcement Learning Approach
Nov 14, 2021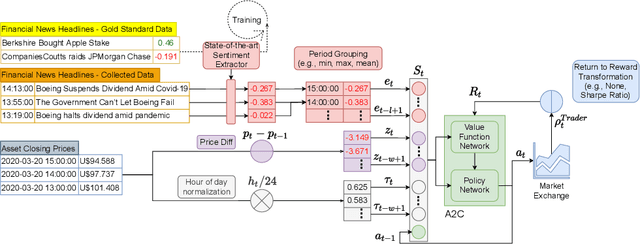


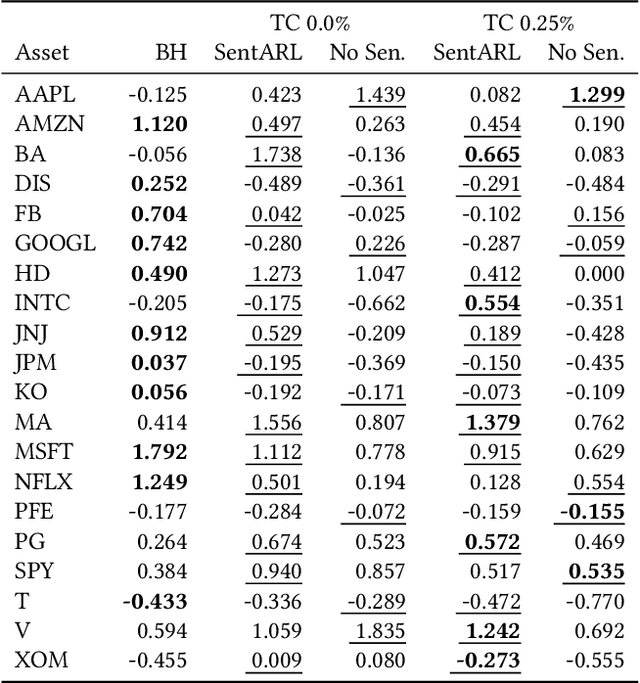
The feasibility of making profitable trades on a single asset on stock exchanges based on patterns identification has long attracted researchers. Reinforcement Learning (RL) and Natural Language Processing have gained notoriety in these single-asset trading tasks, but only a few works have explored their combination. Moreover, some issues are still not addressed, such as extracting market sentiment momentum through the explicit capture of sentiment features that reflect the market condition over time and assessing the consistency and stability of RL results in different situations. Filling this gap, we propose the Sentiment-Aware RL (SentARL) intelligent trading system that improves profit stability by leveraging market mood through an adaptive amount of past sentiment features drawn from textual news. We evaluated SentARL across twenty assets, two transaction costs, and five different periods and initializations to show its consistent effectiveness against baselines. Subsequently, this thorough assessment allowed us to identify the boundary between news coverage and market sentiment regarding the correlation of price-time series above which SentARL's effectiveness is outstanding.