 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound-to-Imagination: Unsupervised Crossmodal Translation Using Deep Dense Network Architecture
Jun 02, 2021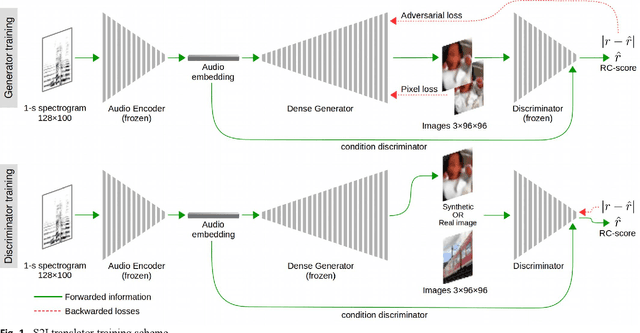
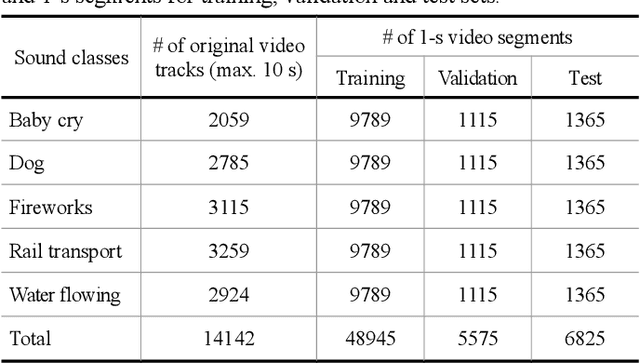


The motivation of our research is to develop a sound-to-image (S2I) translation system for enabling a human receiver to visually infer the occurrence of sound related events. We expect the computer to 'imagine' the scene from the captured sound, generating original images that picture the sound emitting source. Previous studies on similar topics opted for simplified approaches using data with low content diversity and/or strong supervision. Differently, we propose to perform unsupervised S2I translation using thousands of distinct and unknown scenes, with slightly pre-cleaned data, just enough to guarantee aural-visual semantic coherence. To that end, we employ conditional generative adversarial networks (GANs) with a deep densely connected generator. Besides, we implemented a moving-average adversarial loss to address GANs training instability. Though the specified S2I translation problem is quite challenging, we were able to generalize the translator model enough to obtain more than 14%, in average, of interpretable and semantically coherent images translated from unknown sounds. Additionally, we present a solution using informativity classifiers to perform quantitative evaluation of S2I translation.
Mobile Sound Recognition for the Deaf and Hard of Hearing
Oct 19, 2018Human perception of surrounding events is strongly dependent on audio cues. Thus, acoustic insulation can seriously impact situational awareness. We present an exploratory study in the domain of assistive computing, eliciting requirements and presenting solutions to problems found in the development of an environmental sound recognition system, which aims to assist deaf and hard of hearing people in the perception of sounds. To take advantage of smartphones computational ubiquity, we propose a system that executes all processing on the device itself, from audio features extraction to recognition and visual presentation of results. Our application also presents the confidence level of the classification to the user. A test of the system conducted with deaf users provided important and inspiring feedback from participants.