 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSound-to-Imagination: Unsupervised Crossmodal Translation Using Deep Dense Network Architecture
Jun 02, 2021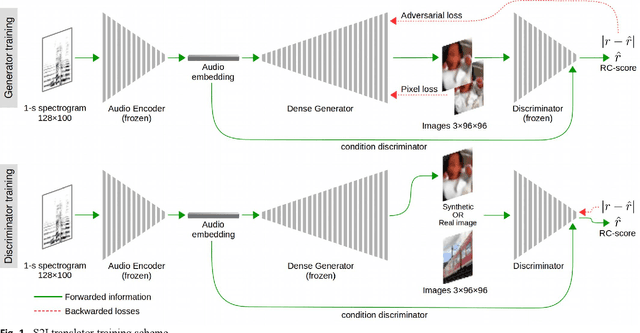
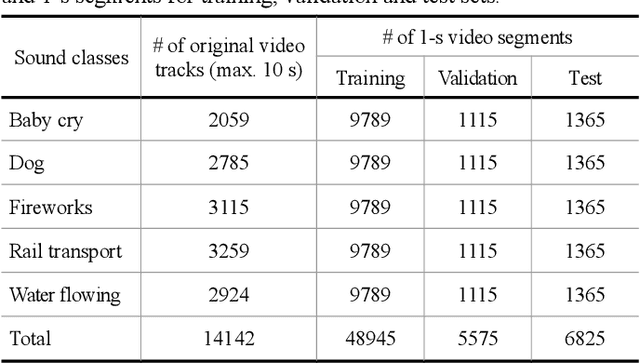


The motivation of our research is to develop a sound-to-image (S2I) translation system for enabling a human receiver to visually infer the occurrence of sound related events. We expect the computer to 'imagine' the scene from the captured sound, generating original images that picture the sound emitting source. Previous studies on similar topics opted for simplified approaches using data with low content diversity and/or strong supervision. Differently, we propose to perform unsupervised S2I translation using thousands of distinct and unknown scenes, with slightly pre-cleaned data, just enough to guarantee aural-visual semantic coherence. To that end, we employ conditional generative adversarial networks (GANs) with a deep densely connected generator. Besides, we implemented a moving-average adversarial loss to address GANs training instability. Though the specified S2I translation problem is quite challenging, we were able to generalize the translator model enough to obtain more than 14%, in average, of interpretable and semantically coherent images translated from unknown sounds. Additionally, we present a solution using informativity classifiers to perform quantitative evaluation of S2I translation.