 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparable DeepONet: Breaking the Curse of Dimensionality in Physics-Informed Machine Learning
Jul 25, 2024
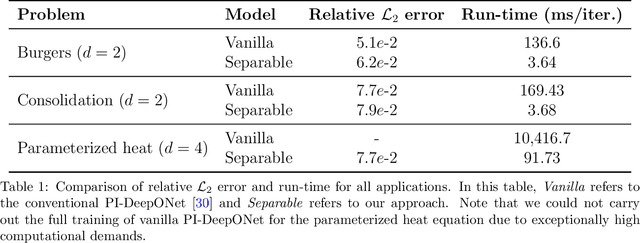
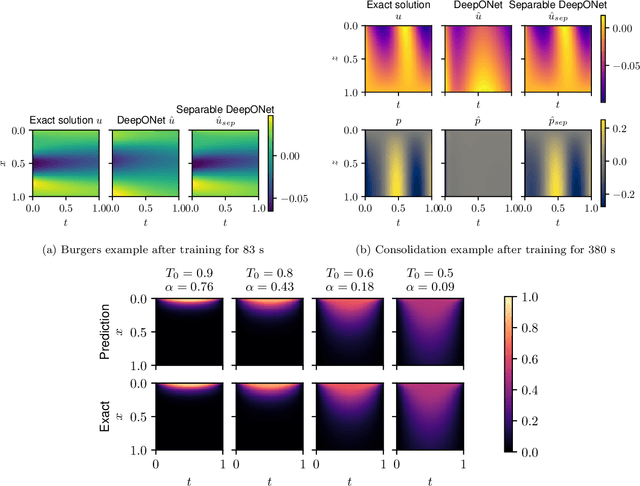
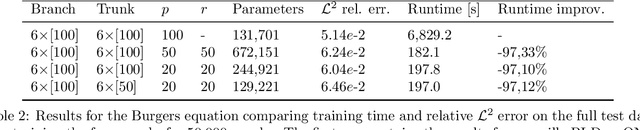
The deep operator network (DeepONet) is a popular neural operator architecture that has shown promise in solving partial differential equations (PDEs) by using deep neural networks to map between infinite-dimensional function spaces. In the absence of labeled datasets, we utilize the PDE residual loss to learn the physical system, an approach known as physics-informed DeepONet. This method faces significant computational challenges, primarily due to the curse of dimensionality, as the computational cost increases exponentially with finer discretization. In this paper, we introduce the Separable DeepONet framework to address these challenges and improve scalability for high-dimensional PDEs. Our approach involves a factorization technique where sub-networks handle individual one-dimensional coordinates, thereby reducing the number of forward passes and the size of the Jacobian matrix. By using forward-mode automatic differentiation, we further optimize the computational cost related to the Jacobian matrix. As a result, our modifications lead to a linear scaling of computational cost with discretization density, making Separable DeepONet suitable for high-dimensional PDEs. We validate the effectiveness of the separable architecture through three benchmark PDE models: the viscous Burgers equation, Biot's consolidation theory, and a parametrized heat equation. In all cases, our proposed framework achieves comparable or improved accuracy while significantly reducing computational time compared to conventional DeepONet. These results demonstrate the potential of Separable DeepONet in efficiently solving complex, high-dimensional PDEs, advancing the field of physics-informed machine learning.