 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Disagreement Problem in Faithfulness Metrics
Nov 13, 2023The field of explainable artificial intelligence (XAI) aims to explain how black-box machine learning models work. Much of the work centers around the holy grail of providing post-hoc feature attributions to any model architecture. While the pace of innovation around novel methods has slowed down, the question remains of how to choose a method, and how to make it fit for purpose. Recently, efforts around benchmarking XAI methods have suggested metrics for that purpose -- but there are many choices. That bounty of choice still leaves an end user unclear on how to proceed. This paper focuses on comparing metrics with the aim of measuring faithfulness of local explanations on tabular classification problems -- and shows that the current metrics don't agree; leaving users unsure how to choose the most faithful explanations.
Making Intelligence: Ethics, IQ, and ML Benchmarks
Sep 01, 2022The ML community recognizes the importance of anticipating and mitigating the potential negative impacts of benchmark research. In this position paper, we argue that more attention needs to be paid to areas of ethical risk that lie at the technical and scientific core of ML benchmarks. We identify overlooked structural similarities between human IQ and ML benchmarks. Human intelligence and ML benchmarks share similarities in setting standards for describing, evaluating and comparing performance on tasks relevant to intelligence. This enables us to unlock lessons from feminist philosophy of science scholarship that need to be considered by the ML benchmark community. Finally, we outline practical recommendations for benchmark research ethics and ethics review.
Should attention be all we need? The epistemic and ethical implications of unification in machine learning
May 09, 2022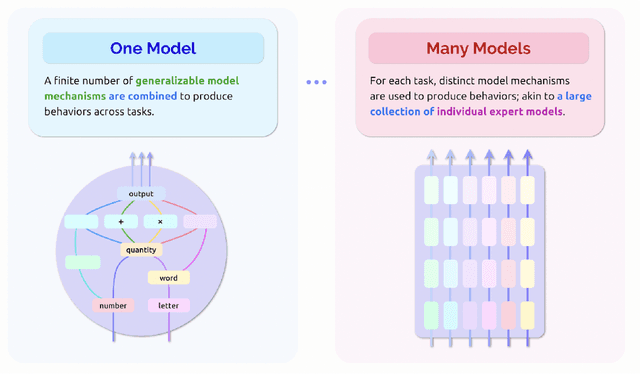
"Attention is all you need" has become a fundamental precept in machine learning research. Originally designed for machine translation, transformers and the attention mechanisms that underpin them now find success across many problem domains. With the apparent domain-agnostic success of transformers, many researchers are excited that similar model architectures can be successfully deployed across diverse applications in vision, language and beyond. We consider the benefits and risks of these waves of unification on both epistemic and ethical fronts. On the epistemic side, we argue that many of the arguments in favor of unification in the natural sciences fail to transfer over to the machine learning case, or transfer over only under assumptions that might not hold. Unification also introduces epistemic risks related to portability, path dependency, methodological diversity, and increased black-boxing. On the ethical side, we discuss risks emerging from epistemic concerns, further marginalizing underrepresented perspectives, the centralization of power, and having fewer models across more domains of application