 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs there Gender bias and stereotype in Portuguese Word Embeddings?
Oct 10, 2018

In this work, we propose an analysis of the presence of gender bias associated with professions in Portuguese word embeddings. The objective of this work is to study gender implications related to stereotyped professions for women and men in the context of the Portuguese language.
Modeling, comprehending and summarizing textual content by graphs
Jul 01, 2018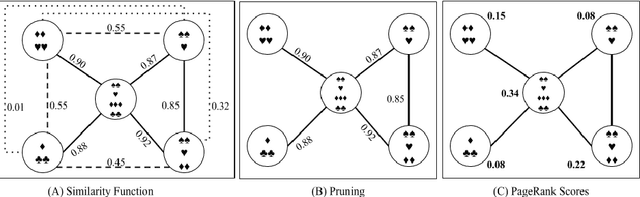

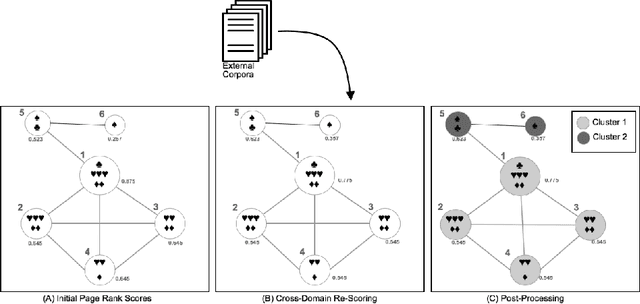
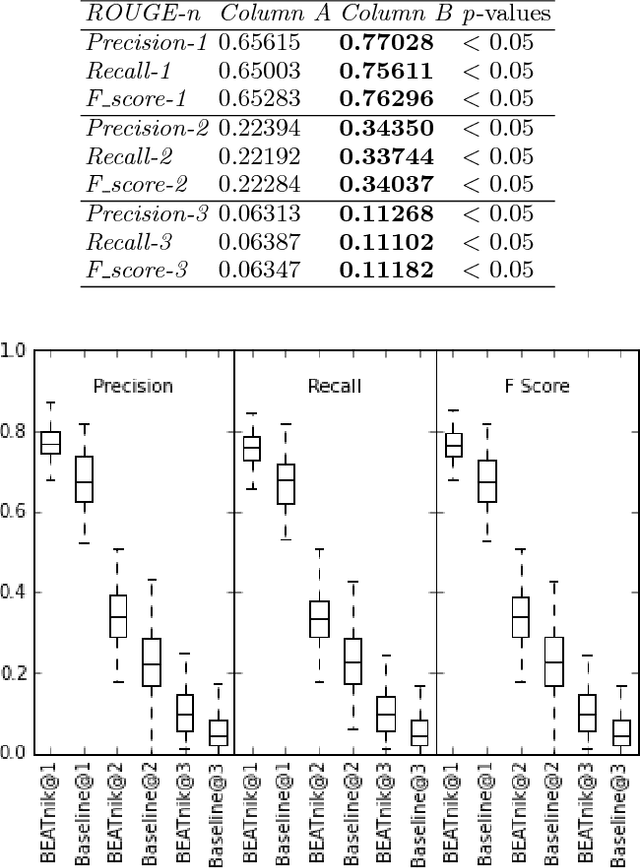
Automatic Text Summarization strategies have been successfully employed to digest text collections and extract its essential content. Usually, summaries are generated using textual corpora that belongs to the same domain area where the summary will be used. Nonetheless, there are special cases where it is not found enough textual sources, and one possible alternative is to generate a summary from a different domain. One manner to summarize texts consists of using a graph model. This model allows giving more importance to words corresponding to the main concepts from the target domain found in the summarized text. This gives the reader an overview of the main text concepts as well as their relationships. However, this kind of summarization presents a significant number of repeated terms when compared to human-generated summaries. In this paper, we present an approach to produce graph-model extractive summaries of texts, meeting the target domain exigences and treating the terms repetition problem. To evaluate the proposition, we performed a series of experiments showing that the proposed approach statistically improves the performance of a model based on Graph Centrality, achieving better coverage, accuracy, and recall.