 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Computer Vision with Knowledge: a Rummikub Case Study
Nov 27, 2024


Artificial Neural Networks excel at identifying individual components in an image. However, out-of-the-box, they do not manage to correctly integrate and interpret these components as a whole. One way to alleviate this weakness is to expand the network with explicit knowledge and a separate reasoning component. In this paper, we evaluate an approach to this end, applied to the solving of the popular board game Rummikub. We demonstrate that, for this particular example, the added background knowledge is equally valuable as two-thirds of the data set, and allows to bring down the training time to half the original time.
EmoCAM: Toward Understanding What Drives CNN-based Emotion Recognition
Jul 19, 2024



Convolutional Neural Networks are particularly suited for image analysis tasks, such as Image Classification, Object Recognition or Image Segmentation. Like all Artificial Neural Networks, however, they are "black box" models, and suffer from poor explainability. This work is concerned with the specific downstream task of Emotion Recognition from images, and proposes a framework that combines CAM-based techniques with Object Detection on a corpus level to better understand on which image cues a particular model, in our case EmoNet, relies to assign a specific emotion to an image. We demonstrate that the model mostly focuses on human characteristics, but also explore the pronounced effect of specific image modifications.
FindingEmo: An Image Dataset for Emotion Recognition in the Wild
Feb 02, 2024We introduce FindingEmo, a new image dataset containing annotations for 25k images, specifically tailored to Emotion Recognition. Contrary to existing datasets, it focuses on complex scenes depicting multiple people in various naturalistic, social settings, with images being annotated as a whole, thereby going beyond the traditional focus on faces or single individuals. Annotated dimensions include Valence, Arousal and Emotion label, with annotations gathered using Prolific. Together with the annotations, we release the list of URLs pointing to the original images, as well as all associated source code.
Compressing Word Embeddings Using Syllables
Jan 13, 2022
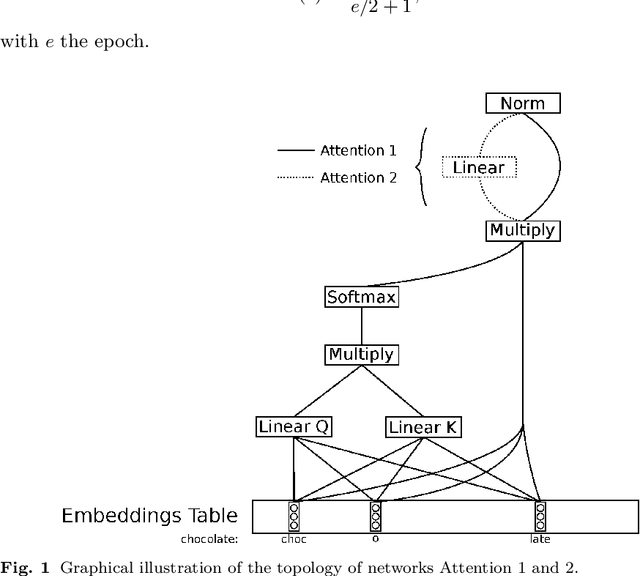

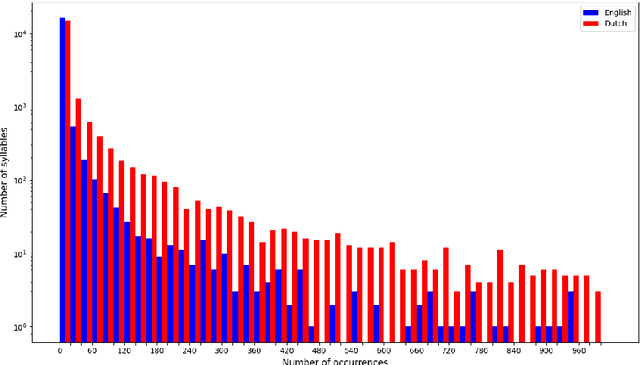
This work examines the possibility of using syllable embeddings, instead of the often used $n$-gram embeddings, as subword embeddings. We investigate this for two languages: English and Dutch. To this end, we also translated two standard English word embedding evaluation datasets, WordSim353 and SemEval-2017, to Dutch. Furthermore, we provide the research community with data sets of syllabic decompositions for both languages. We compare our approach to full word and $n$-gram embeddings. Compared to full word embeddings, we obtain English models that are 20 to 30 times smaller while retaining 80% of the performance. For Dutch, models are 15 times smaller for 70% performance retention. Although less accurate than the $n$-gram baseline we used, our models can be trained in a matter of minutes, as opposed to hours for the $n$-gram approach. We identify a path toward upgrading performance in future work. All code is made publicly available, as well as our collected English and Dutch syllabic decompositions and Dutch evaluation set translations.