 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Word Embeddings Using Syllables
Paper and Code

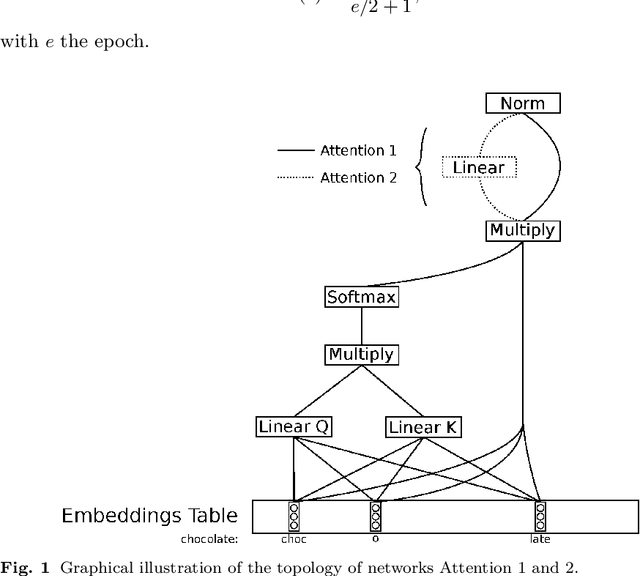

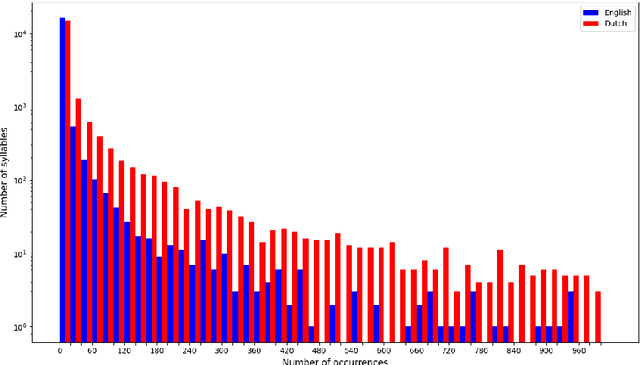
This work examines the possibility of using syllable embeddings, instead of the often used $n$-gram embeddings, as subword embeddings. We investigate this for two languages: English and Dutch. To this end, we also translated two standard English word embedding evaluation datasets, WordSim353 and SemEval-2017, to Dutch. Furthermore, we provide the research community with data sets of syllabic decompositions for both languages. We compare our approach to full word and $n$-gram embeddings. Compared to full word embeddings, we obtain English models that are 20 to 30 times smaller while retaining 80% of the performance. For Dutch, models are 15 times smaller for 70% performance retention. Although less accurate than the $n$-gram baseline we used, our models can be trained in a matter of minutes, as opposed to hours for the $n$-gram approach. We identify a path toward upgrading performance in future work. All code is made publicly available, as well as our collected English and Dutch syllabic decompositions and Dutch evaluation set translations.