 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLumen: A Machine Learning Framework to Expose Influence Cues in Text
Jul 12, 2021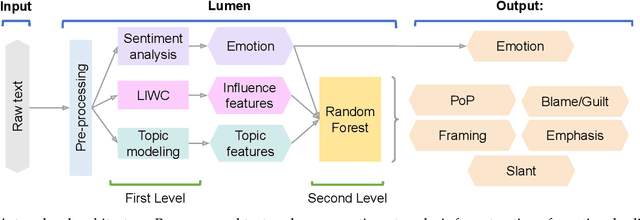
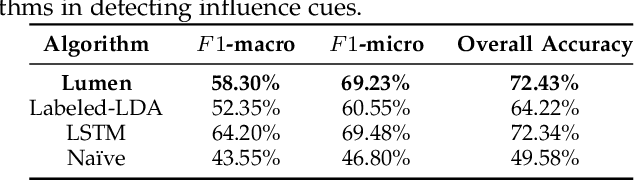
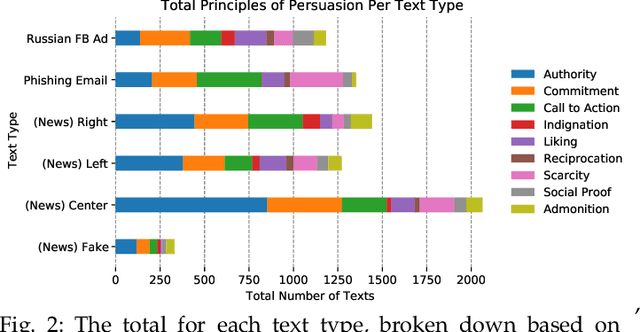
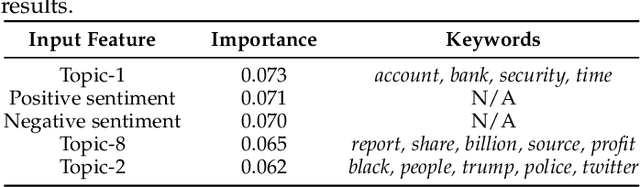
Phishing and disinformation are popular social engineering attacks with attackers invariably applying influence cues in texts to make them more appealing to users. We introduce Lumen, a learning-based framework that exposes influence cues in text: (i) persuasion, (ii) framing, (iii) emotion, (iv) objectivity/subjectivity, (v) guilt/blame, and (vi) use of emphasis. Lumen was trained with a newly developed dataset of 3K texts comprised of disinformation, phishing, hyperpartisan news, and mainstream news. Evaluation of Lumen in comparison to other learning models showed that Lumen and LSTM presented the best F1-micro score, but Lumen yielded better interpretability. Our results highlight the promise of ML to expose influence cues in text, towards the goal of application in automatic labeling tools to improve the accuracy of human-based detection and reduce the likelihood of users falling for deceptive online content.