 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning structure-from-motion from motion
Oct 19, 2018
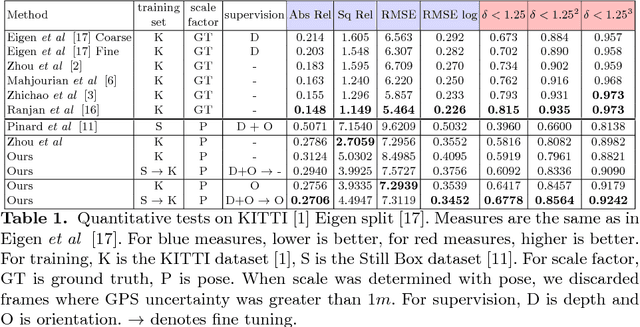


This work is based on a questioning of the quality metrics used by deep neural networks performing depth prediction from a single image, and then of the usability of recently published works on unsupervised learning of depth from videos. To overcome their limitations, we propose to learn in the same unsupervised manner a depth map inference system from monocular videos that takes a pair of images as input. This algorithm actually learns structure-from-motion from motion, and not only structure from context appearance. The scale factor issue is explicitly treated, and the absolute depth map can be estimated from camera displacement magnitude, which can be easily measured from cheap external sensors. Our solution is also much more robust with respect to domain variation and adaptation via fine tuning, because it does not rely entirely in depth from context. Two use cases are considered, unstabilized moving camera videos, and stabilized ones. This choice is motivated by the UAV (for Unmanned Aerial Vehicle) use case that generally provides reliable orientation measurement. We provide a set of experiments showing that, used in real conditions where only speed can be known, our network outperforms competitors for most depth quality measures. Results are given on the well known KITTI dataset, which provides robust stabilization for our second use case, but also contains moving scenes which are very typical of the in-car road context. We then present results on a synthetic dataset that we believe to be more representative of typical UAV scenes. Lastly, we present two domain adaptation use cases showing superior robustness of our method compared to single view depth algorithms, which indicates that it is better suited for highly variable visual contexts.
Multi range Real-time depth inference from a monocular stabilized footage using a Fully Convolutional Neural Network
Sep 12, 2018

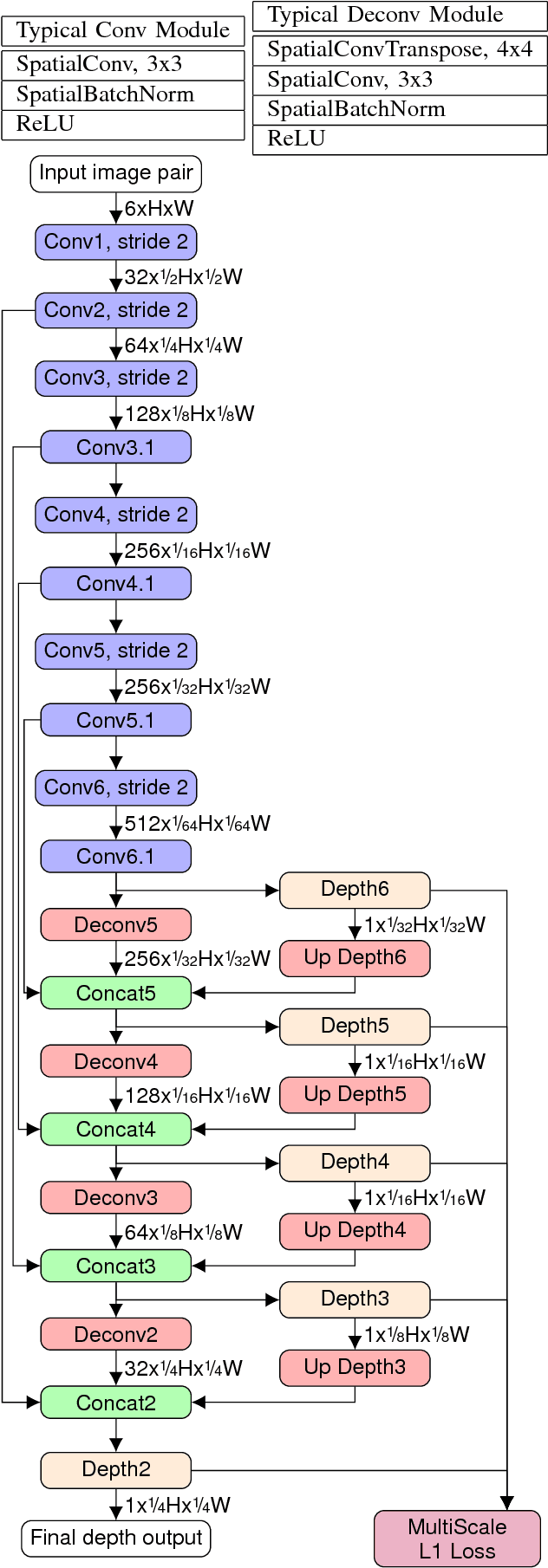

Using a neural network architecture for depth map inference from monocular stabilized videos with application to UAV videos in rigid scenes, we propose a multi-range architecture for unconstrained UAV flight, leveraging flight data from sensors to make accurate depth maps for uncluttered outdoor environment. We try our algorithm on both synthetic scenes and real UAV flight data. Quantitative results are given for synthetic scenes with a slightly noisy orientation, and show that our multi-range architecture improves depth inference. Along with this article is a video that present our results more thoroughly.
* arXiv admin note: text overlap with arXiv:1809.04453
End-to-end depth from motion with stabilized monocular videos
Sep 12, 2018


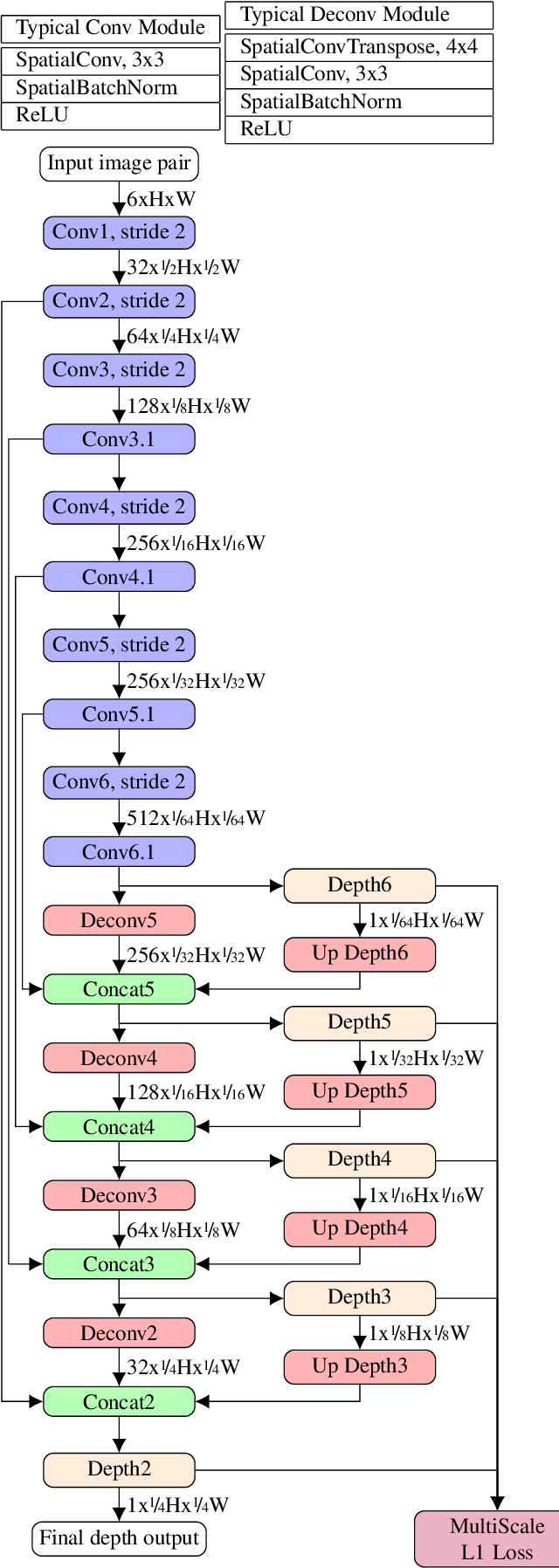
We propose a depth map inference system from monocular videos based on a novel dataset for navigation that mimics aerial footage from gimbal stabilized monocular camera in rigid scenes. Unlike most navigation datasets, the lack of rotation implies an easier structure from motion problem which can be leveraged for different kinds of tasks such as depth inference and obstacle avoidance. We also propose an architecture for end-to-end depth inference with a fully convolutional network. Results show that although tied to camera inner parameters, the problem is locally solvable and leads to good quality depth prediction.