 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Deep Reinforcement Learning for Large-scale Traffic Signal Control
Mar 11, 2019
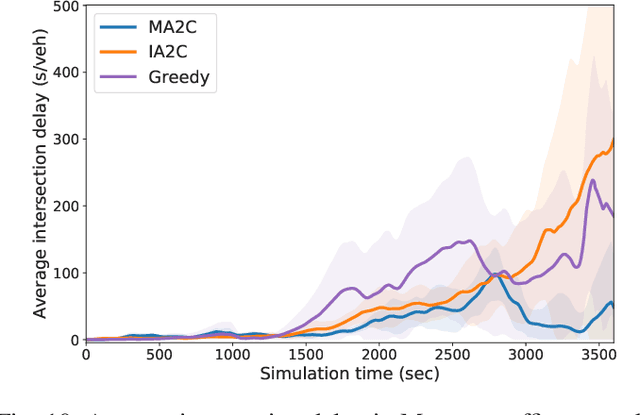


Reinforcement learning (RL) is a promising data-driven approach for adaptive traffic signal control (ATSC) in complex urban traffic networks, and deep neural networks further enhance its learning power. However, centralized RL is infeasible for large-scale ATSC due to the extremely high dimension of the joint action space. Multi-agent RL (MARL) overcomes the scalability issue by distributing the global control to each local RL agent, but it introduces new challenges: now the environment becomes partially observable from the viewpoint of each local agent due to limited communication among agents. Most existing studies in MARL focus on designing efficient communication and coordination among traditional Q-learning agents. This paper presents, for the first time, a fully scalable and decentralized MARL algorithm for the state-of-the-art deep RL agent: advantage actor critic (A2C), within the context of ATSC. In particular, two methods are proposed to stabilize the learning procedure, by improving the observability and reducing the learning difficulty of each local agent. The proposed multi-agent A2C is compared against independent A2C and independent Q-learning algorithms, in both a large synthetic traffic grid and a large real-world traffic network of Monaco city, under simulated peak-hour traffic dynamics. Results demonstrate its optimality, robustness, and sample efficiency over other state-of-the-art decentralized MARL algorithms.