 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Similarity Learning Loss Functions in Data Transformation for Class Imbalance
Dec 16, 2023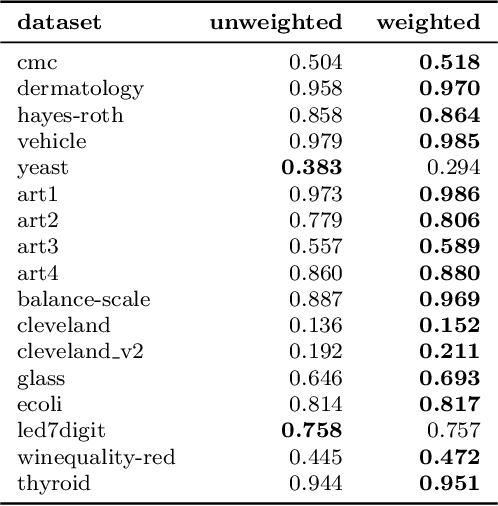


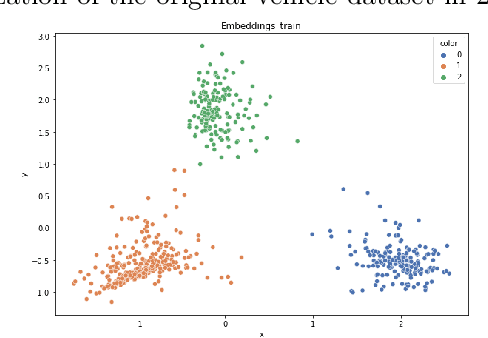
Improving the classification of multi-class imbalanced data is more difficult than its two-class counterpart. In this paper, we use deep neural networks to train new representations of tabular multi-class data. Unlike the typically developed re-sampling pre-processing methods, our proposal modifies the distribution of features, i.e. the positions of examples in the learned embedded representation, and it does not modify the class sizes. To learn such embedded representations we introduced various definitions of triplet loss functions: the simplest one uses weights related to the degree of class imbalance, while the next proposals are intended for more complex distributions of examples and aim to generate a safe neighborhood of minority examples. Similarly to the resampling approaches, after applying such preprocessing, different classifiers can be trained on new representations. Experiments with popular multi-class imbalanced benchmark data sets and three classifiers showed the advantage of the proposed approach over popular pre-processing methods as well as basic versions of neural networks with classical loss function formulations.