 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning for Doom using Unsupervised Auxiliary Tasks
Jul 05, 2018
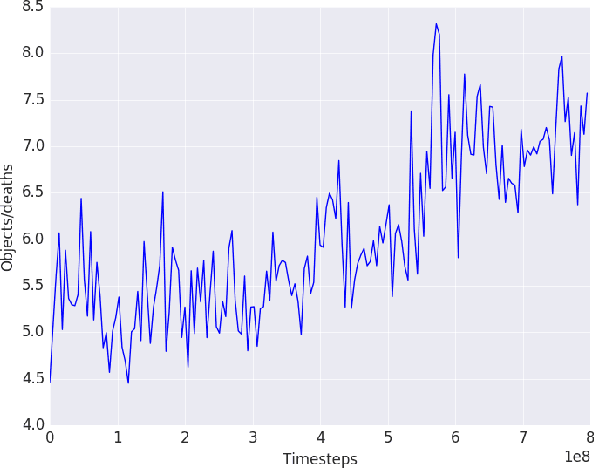
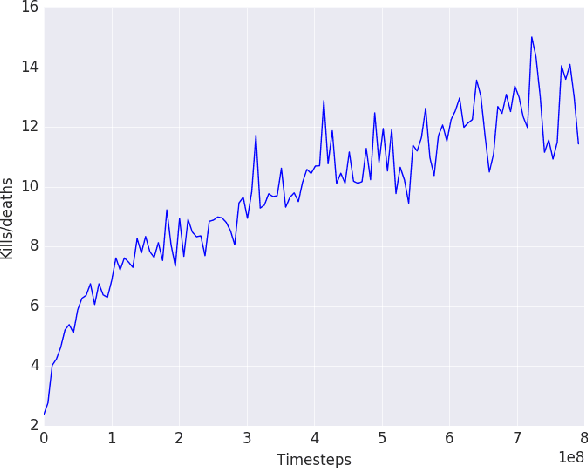

Recent developments in deep reinforcement learning have enabled the creation of agents for solving a large variety of games given a visual input. These methods have been proven successful for 2D games, like the Atari games, or for simple tasks, like navigating in mazes. It is still an open question, how to address more complex environments, in which the reward is sparse and the state space is huge. In this paper we propose a divide and conquer deep reinforcement learning solution and we test our agent in the first person shooter (FPS) game of Doom. Our work is based on previous works in deep reinforcement learning and in Doom agents. We also present how our agent is able to perform better in unknown environments compared to a state of the art reinforcement learning algorithm.