 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMolecular Structure Extraction From Documents Using Deep Learning
Feb 14, 2018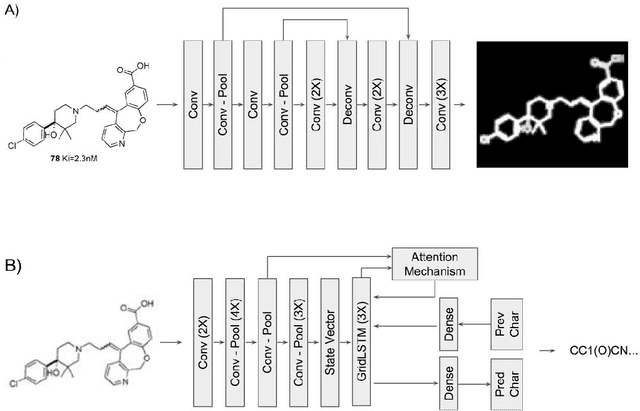

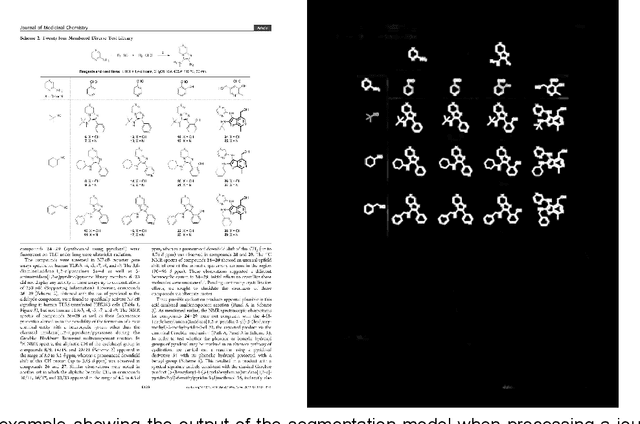
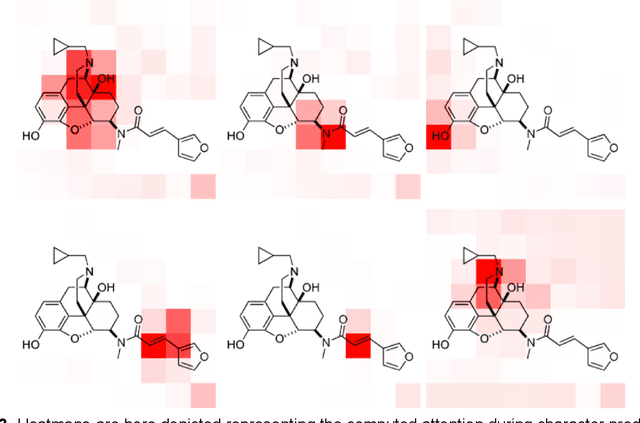
Chemical structure extraction from documents remains a hard problem due to both false positive identification of structures during segmentation and errors in the predicted structures. Current approaches rely on handcrafted rules and subroutines that perform reasonably well generally, but still routinely encounter situations where recognition rates are not yet satisfactory and systematic improvement is challenging. Complications impacting performance of current approaches include the diversity in visual styles used by various software to render structures, the frequent use of ad hoc annotations, and other challenges related to image quality, including resolution and noise. We here present end-to-end deep learning solutions for both segmenting molecular structures from documents and for predicting chemical structures from these segmented images. This deep learning-based approach does not require any handcrafted features, is learned directly from data, and is robust against variations in image quality and style. Using the deep-learning approach described herein we show that it is possible to perform well on both segmentation and prediction of low resolution images containing moderately sized molecules found in journal articles and patents.