 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivate Speech Characterization with Secure Multiparty Computation
Jul 01, 2020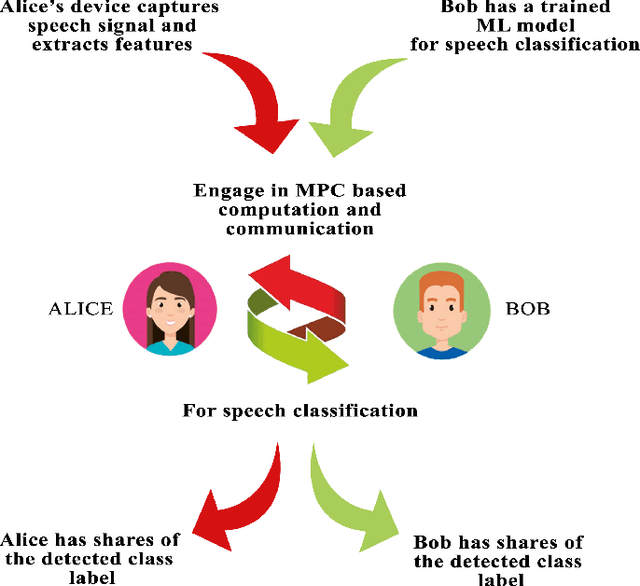

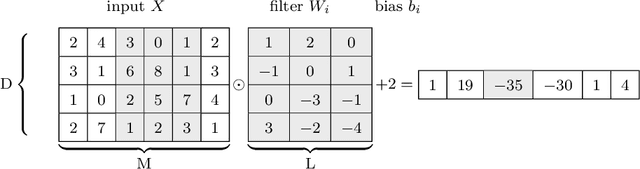
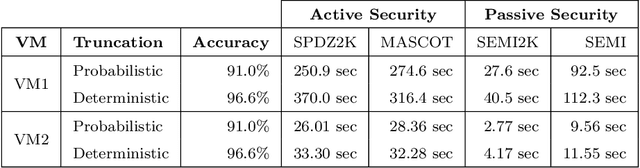
Deep learning in audio signal processing, such as human voice audio signal classification, is a rich application area of machine learning. Legitimate use cases include voice authentication, gunfire detection, and emotion recognition. While there are clear advantages to automated human speech classification, application developers can gain knowledge beyond the professed scope from unprotected audio signal processing. In this paper we propose the first privacy-preserving solution for deep learning-based audio classification that is provably secure. Our approach, which is based on Secure Multiparty Computation, allows to classify a speech signal of one party (Alice) with a deep neural network of another party (Bob) without Bob ever seeing Alice's speech signal in an unencrypted manner. As threat models, we consider both passive security, i.e. with semi-honest parties who follow the instructions of the cryptographic protocols, as well as active security, i.e. with malicious parties who deviate from the protocols. We evaluate the efficiency-security-accuracy trade-off of the proposed solution in a use case for privacy-preserving emotion detection from speech with a convolutional neural network. In the semi-honest case we can classify a speech signal in under 0.3 sec; in the malicious case it takes $\sim$1.6 sec. In both cases there is no leakage of information, and we achieve classification accuracies that are the same as when computations are done on unencrypted data.