Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning for Long-Context Sentiment Analysis on Infrastructure Project Opinions
Oct 15, 2024
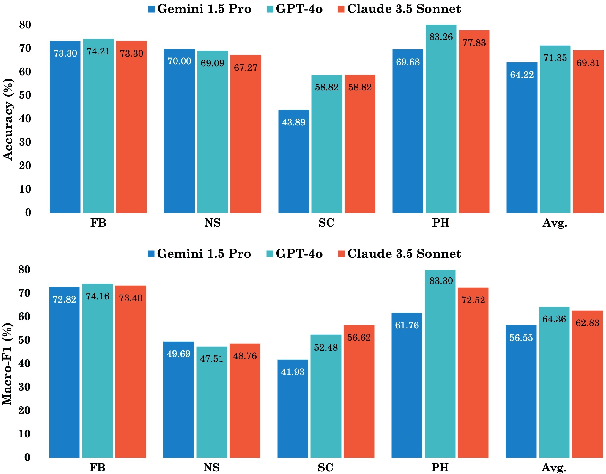

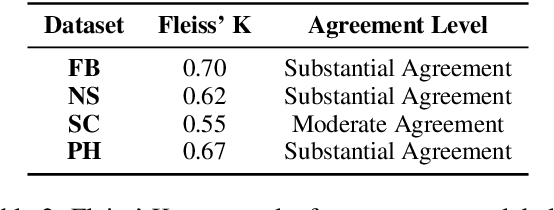
Large language models (LLMs) have achieved impressive results across various tasks. However, they still struggle with long-context documents. This study evaluates the performance of three leading LLMs: GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro on lengthy, complex, and opinion-varying documents concerning infrastructure projects, under both zero-shot and few-shot scenarios. Our results indicate that GPT-4o excels in zero-shot scenarios for simpler, shorter documents, while Claude 3.5 Sonnet surpasses GPT-4o in handling more complex, sentiment-fluctuating opinions. In few-shot scenarios, Claude 3.5 Sonnet outperforms overall, while GPT-4o shows greater stability as the number of demonstrations increases.
Via