 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCSTA: CNN-based Spatiotemporal Attention for Video Summarization
May 21, 2024Video summarization aims to generate a concise representation of a video, capturing its essential content and key moments while reducing its overall length. Although several methods employ attention mechanisms to handle long-term dependencies, they often fail to capture the visual significance inherent in frames. To address this limitation, we propose a CNN-based SpatioTemporal Attention (CSTA) method that stacks each feature of frames from a single video to form image-like frame representations and applies 2D CNN to these frame features. Our methodology relies on CNN to comprehend the inter and intra-frame relations and to find crucial attributes in videos by exploiting its ability to learn absolute positions within images. In contrast to previous work compromising efficiency by designing additional modules to focus on spatial importance, CSTA requires minimal computational overhead as it uses CNN as a sliding window. Extensive experiments on two benchmark datasets (SumMe and TVSum) demonstrate that our proposed approach achieves state-of-the-art performance with fewer MACs compared to previous methods. Codes are available at https://github.com/thswodnjs3/CSTA.
A Daily Tourism Demand Prediction Framework Based on Multi-head Attention CNN: The Case of The Foreign Entrant in South Korea
Dec 01, 2021
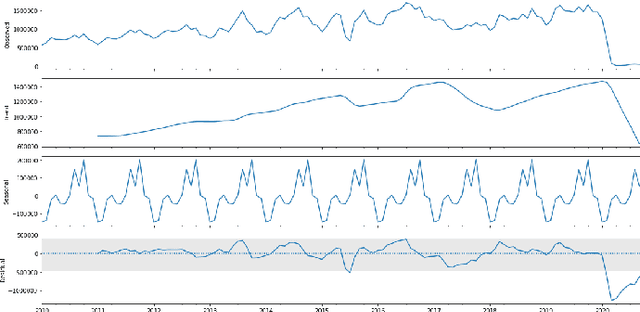
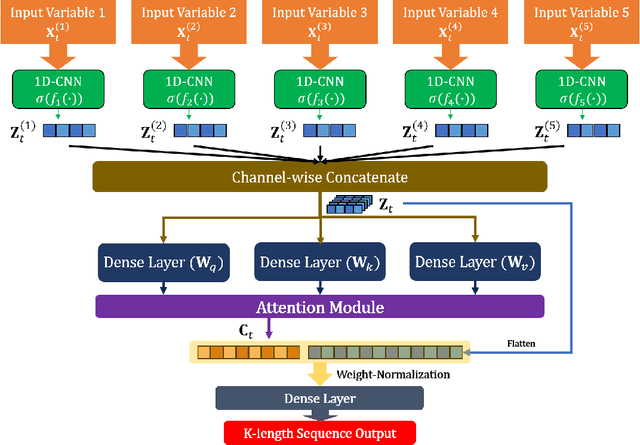

Developing an accurate tourism forecasting model is essential for making desirable policy decisions for tourism management. Early studies on tourism management focus on discovering external factors related to tourism demand. Recent studies utilize deep learning in demand forecasting along with these external factors. They mainly use recursive neural network models such as LSTM and RNN for their frameworks. However, these models are not suitable for use in forecasting tourism demand. This is because tourism demand is strongly affected by changes in various external factors, and recursive neural network models have limitations in handling these multivariate inputs. We propose a multi-head attention CNN model (MHAC) for addressing these limitations. The MHAC uses 1D-convolutional neural network to analyze temporal patterns and the attention mechanism to reflect correlations between input variables. This model makes it possible to extract spatiotemporal characteristics from time-series data of various variables. We apply our forecasting framework to predict inbound tourist changes in South Korea by considering external factors such as politics, disease, season, and attraction of Korean culture. The performance results of extensive experiments show that our method outperforms other deep-learning-based prediction frameworks in South Korea tourism forecasting.
FedCCEA : A Practical Approach of Client Contribution Evaluation for Federated Learning
Jun 04, 2021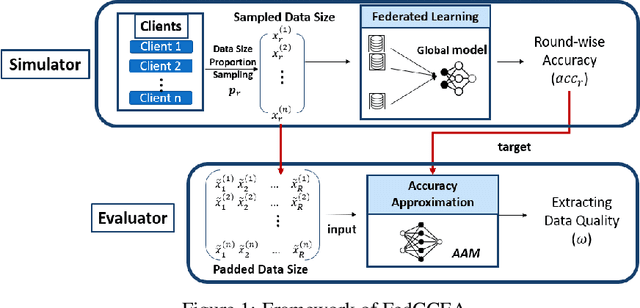



Client contribution evaluation, also known as data valuation, is a crucial approach in federated learning(FL) for client selection and incentive allocation. However, due to restrictions of accessibility of raw data, only limited information such as local weights and local data size of each client is open for quantifying the client contribution. Using data size from available information, we introduce an empirical evaluation method called Federated Client Contribution Evaluation through Accuracy Approximation(FedCCEA). This method builds the Accuracy Approximation Model(AAM), which estimates a simulated test accuracy using inputs of sampled data size and extracts the clients' data quality and data size to measure client contribution. FedCCEA strengthens some advantages: (1) enablement of data size selection to the clients, (2) feasible evaluation time regardless of the number of clients, and (3) precise estimation in non-IID settings. We demonstrate the superiority of FedCCEA compared to previous methods through several experiments: client contribution distribution, client removal, and robustness test to partial participation.
Facial Manipulation Detection Based on the Color Distribution Analysis in Edge Region
Feb 02, 2021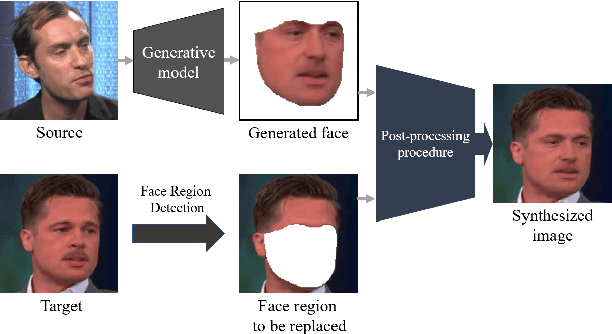
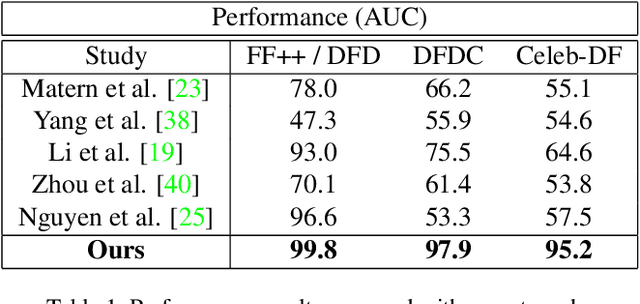


In this work, we present a generalized and robust facial manipulation detection method based on color distribution analysis of the vertical region of edge in a manipulated image. Most of the contemporary facial manipulation method involves pixel correction procedures for reducing awkwardness of pixel value differences along the facial boundary in a synthesized image. For this procedure, there are distinctive differences in the facial boundary between face manipulated image and unforged natural image. Also, in the forged image, there should be distinctive and unnatural features in the gap distribution between facial boundary and background edge region because it tends to damage the natural effect of lighting. We design the neural network for detecting face-manipulated image with these distinctive features in facial boundary and background edge. Our extensive experiments show that our method outperforms other existing face manipulation detection methods on detecting synthesized face image in various datasets regardless of whether it has participated in training.