 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning of Molecular Data for Task-Specific Objectives
Aug 20, 2024Active learning (AL) has shown promise for being a particularly data-efficient machine learning approach. Yet, its performance depends on the application and it is not clear when AL practitioners can expect computational savings. Here, we carry out a systematic AL performance assessment for three diverse molecular datasets and two common scientific tasks: compiling compact, informative datasets and targeted molecular searches. We implemented AL with Gaussian processes (GP) and used the many-body tensor as molecular representation. For the first task, we tested different data acquisition strategies, batch sizes and GP noise settings. AL was insensitive to the acquisition batch size and we observed the best AL performance for the acquisition strategy that combines uncertainty reduction with clustering to promote diversity. However, for optimal GP noise settings, AL did not outperform randomized selection of data points. Conversely, for targeted searches, AL outperformed random sampling and achieved data savings up to 64%. Our analysis provides insight into this task-specific performance difference in terms of target distributions and data collection strategies. We established that the performance of AL depends on the relative distribution of the target molecules in comparison to the total dataset distribution, with the largest computational savings achieved when their overlap is minimal.
Personalized Category Frequency prediction for Buy It Again recommendations
Jul 24, 2023Buy It Again (BIA) recommendations are crucial to retailers to help improve user experience and site engagement by suggesting items that customers are likely to buy again based on their own repeat purchasing patterns. Most existing BIA studies analyze guests personalized behavior at item granularity. A category-based model may be more appropriate in such scenarios. We propose a recommendation system called a hierarchical PCIC model that consists of a personalized category model (PC model) and a personalized item model within categories (IC model). PC model generates a personalized list of categories that customers are likely to purchase again. IC model ranks items within categories that guests are likely to consume within a category. The hierarchical PCIC model captures the general consumption rate of products using survival models. Trends in consumption are captured using time series models. Features derived from these models are used in training a category-grained neural network. We compare PCIC to twelve existing baselines on four standard open datasets. PCIC improves NDCG up to 16 percent while improving recall by around 2 percent. We were able to scale and train (over 8 hours) PCIC on a large dataset of 100M guests and 3M items where repeat categories of a guest out number repeat items. PCIC was deployed and AB tested on the site of a major retailer, leading to significant gains in guest engagement.
Analysis and Understanding of Various Models for Efficient Representation and Accurate Recognition of Human Faces
Feb 14, 2015


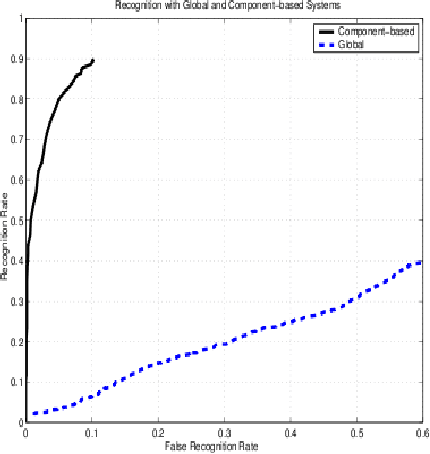
In this paper we have tried to compare the various face recognition models against their classical problems. We look at the methods followed by these approaches and evaluate to what extent they are able to solve the problems. All methods proposed have some drawbacks under certain conditions. To overcome these drawbacks we propose a multi-model approach