 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimensionality-induced information loss of outliers in deep neural networks
Oct 29, 2024Out-of-distribution (OOD) detection is a critical issue for the stable and reliable operation of systems using a deep neural network (DNN). Although many OOD detection methods have been proposed, it remains unclear how the differences between in-distribution (ID) and OOD samples are generated by each processing step inside DNNs. We experimentally clarify this issue by investigating the layer dependence of feature representations from multiple perspectives. We find that intrinsic low dimensionalization of DNNs is essential for understanding how OOD samples become more distinct from ID samples as features propagate to deeper layers. Based on these observations, we provide a simple picture that consistently explains various properties of OOD samples. Specifically, low-dimensional weights eliminate most information from OOD samples, resulting in misclassifications due to excessive attention to dataset bias. In addition, we demonstrate the utility of dimensionality by proposing a dimensionality-aware OOD detection method based on alignment of features and weights, which consistently achieves high performance for various datasets with lower computational cost.
Dual-encoder Bidirectional Generative Adversarial Networks for Anomaly Detection
Dec 22, 2020



Generative adversarial networks (GANs) have shown promise for various problems including anomaly detection. When anomaly detection is performed using GAN models that learn only the features of normal data samples, data that are not similar to normal data are detected as abnormal samples. The present approach is developed by employing a dual-encoder in a bidirectional GAN architecture that is trained simultaneously with a generator and a discriminator network. Through the learning mechanism, the proposed method aims to reduce the problem of bad cycle consistency, in which a bidirectional GAN might not be able to reproduce samples with a large difference between normal and abnormal samples. We assume that bad cycle consistency occurs when the method does not preserve enough information of the sample data. We show that our proposed method performs well in capturing the distribution of normal samples, thereby improving anomaly detection on GAN-based models. Experiments are reported in which our method is applied to publicly available datasets, including application to a brain magnetic resonance imaging anomaly detection system.
Gradient Noise Convolution (GNC): Smoothing Loss Function for Distributed Large-Batch SGD
Jun 26, 2019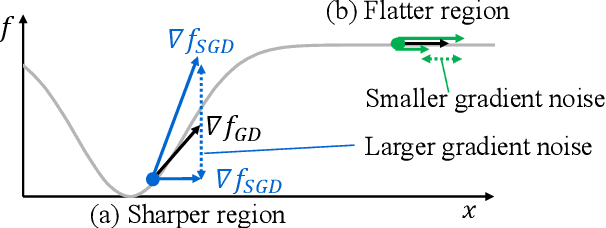

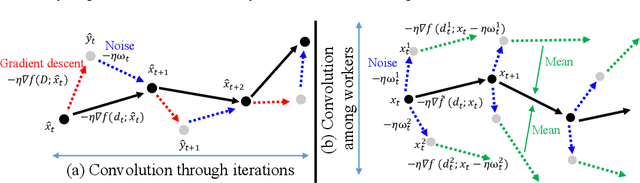
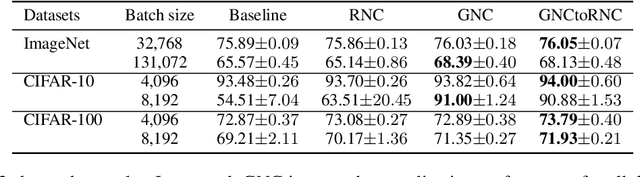
Large-batch stochastic gradient descent (SGD) is widely used for training in distributed deep learning because of its training-time efficiency, however, extremely large-batch SGD leads to poor generalization and easily converges to sharp minima, which prevents naive large-scale data-parallel SGD (DP-SGD) from converging to good minima. To overcome this difficulty, we propose gradient noise convolution (GNC), which effectively smooths sharper minima of the loss function. For DP-SGD, GNC utilizes so-called gradient noise, which is induced by stochastic gradient variation and convolved to the loss function as a smoothing effect. GNC computation can be performed by simply computing the stochastic gradient on each parallel worker and merging them, and is therefore extremely easy to implement. Due to convolving with the gradient noise, which tends to spread along a sharper direction of the loss function, GNC can effectively smooth sharp minima and achieve better generalization, whereas isotropic random noise cannot. We empirically show this effect by comparing GNC with isotropic random noise, and show that it achieves state-of-the-art generalization performance for large-scale deep neural network optimization.