 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation for Semantic Segmentation using One-shot Image-to-Image Translation via Latent Representation Mixing
Dec 07, 2022



Domain adaptation is one of the prominent strategies for handling both domain shift, that is widely encountered in large-scale land use/land cover map calculation, and the scarcity of pixel-level ground truth that is crucial for supervised semantic segmentation. Studies focusing on adversarial domain adaptation via re-styling source domain samples, commonly through generative adversarial networks, have reported varying levels of success, yet they suffer from semantic inconsistencies, visual corruptions, and often require a large number of target domain samples. In this letter, we propose a new unsupervised domain adaptation method for the semantic segmentation of very high resolution images, that i) leads to semantically consistent and noise-free images, ii) operates with a single target domain sample (i.e. one-shot) and iii) at a fraction of the number of parameters required from state-of-the-art methods. More specifically an image-to-image translation paradigm is proposed, based on an encoder-decoder principle where latent content representations are mixed across domains, and a perceptual network module and loss function is further introduced to enforce semantic consistency. Cross-city comparative experiments have shown that the proposed method outperforms state-of-the-art domain adaptation methods. Our source code will be available at \url{https://github.com/Sarmadfismael/LRM_I2I}.
SOMPT22: A Surveillance Oriented Multi-Pedestrian Tracking Dataset
Aug 04, 2022
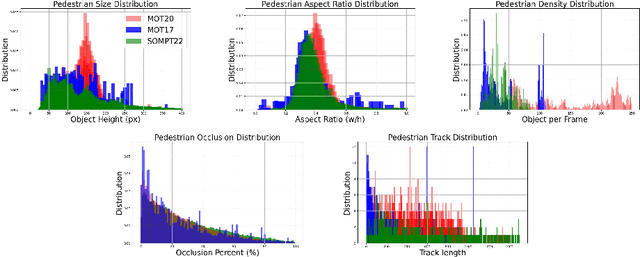


Multi-object tracking (MOT) has been dominated by the use of track by detection approaches due to the success of convolutional neural networks (CNNs) on detection in the last decade. As the datasets and bench-marking sites are published, research direction has shifted towards yielding best accuracy on generic scenarios including re-identification (reID) of objects while tracking. In this study, we narrow the scope of MOT for surveillance by providing a dedicated dataset of pedestrians and focus on in-depth analyses of well performing multi-object trackers to observe the weak and strong sides of state-of-the-art (SOTA) techniques for real-world applications. For this purpose, we introduce SOMPT22 dataset; a new set for multi person tracking with annotated short videos captured from static cameras located on poles with 6-8 meters in height positioned for city surveillance. This provides a more focused and specific benchmarking of MOT for outdoor surveillance compared to public MOT datasets. We analyze MOT trackers classified as one-shot and two-stage with respect to the way of use of detection and reID networks on this new dataset. The experimental results of our new dataset indicate that SOTA is still far from high efficiency, and single-shot trackers are good candidates to unify fast execution and accuracy with competitive performance. The dataset will be available at: sompt22.github.io
Unsupervised Pixel-wise Hyperspectral Anomaly Detection via Autoencoding Adversarial Networks
Jan 21, 2021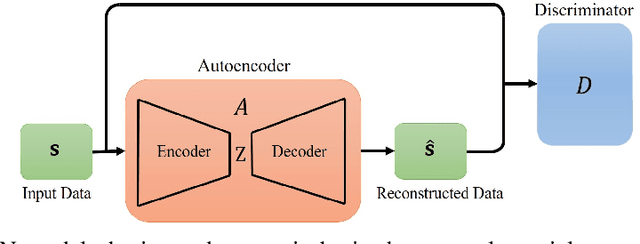

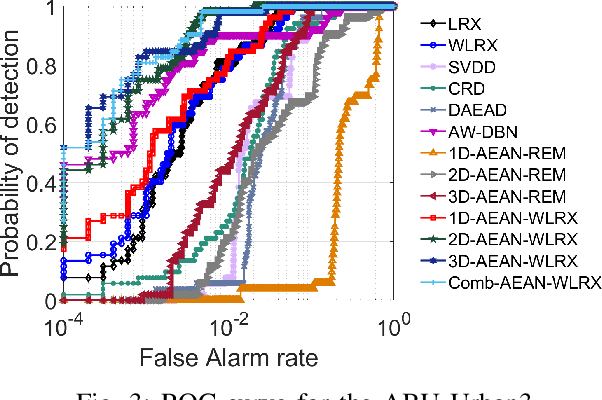

We propose a completely unsupervised pixel-wise anomaly detection method for hyperspectral images. The proposed method consists of three steps called data preparation, reconstruction, and detection. In the data preparation step, we apply a background purification to train the deep network in an unsupervised manner. In the reconstruction step, we propose to use three different deep autoencoding adversarial network (AEAN) models including 1D-AEAN, 2D-AEAN, and 3D-AEAN which are developed for working on spectral, spatial, and joint spectral-spatial domains, respectively. The goal of the AEAN models is to generate synthesized hyperspectral images (HSIs) which are close to real ones. A reconstruction error map (REM) is calculated between the original and the synthesized image pixels. In the detection step, we propose to use a WRX-based detector in which the pixel weights are obtained according to REM. We compare our proposed method with the classical RX, WRX, support vector data description-based (SVDD), collaborative representation-based detector (CRD), adaptive weight deep belief network (AW-DBN) detector and deep autoencoder anomaly detection (DAEAD) method on real hyperspectral datasets. The experimental results show that the proposed approach outperforms other detectors in the benchmark.