 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe eyes know it: FakeET -- An Eye-tracking Database to Understand Deepfake Perception
Jun 18, 2020


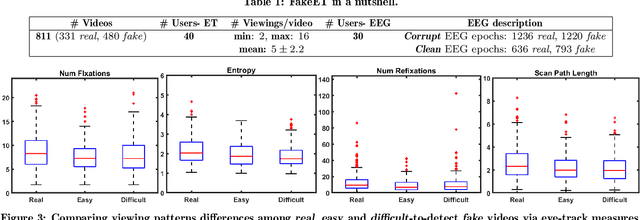
We present \textbf{FakeET}-- an eye-tracking database to understand human visual perception of \emph{deepfake} videos. Given that the principal purpose of deepfakes is to deceive human observers, FakeET is designed to understand and evaluate the ease with which viewers can detect synthetic video artifacts. FakeET contains viewing patterns compiled from 40 users via the \emph{Tobii} desktop eye-tracker for 811 videos from the \textit{Google Deepfake} dataset, with a minimum of two viewings per video. Additionally, EEG responses acquired via the \emph{Emotiv} sensor are also available. The compiled data confirms (a) distinct eye movement characteristics for \emph{real} vs \emph{fake} videos; (b) utility of the eye-track saliency maps for spatial forgery localization and detection, and (c) Error Related Negativity (ERN) triggers in the EEG responses, and the ability of the \emph{raw} EEG signal to distinguish between \emph{real} and \emph{fake} videos.
Not made for each other- Audio-Visual Dissonance-based Deepfake Detection and Localization
Jun 01, 2020



We propose detection of deepfake videos based on the dissimilarity between the audio and visual modalities, termed as the Modality Dissonance Score (MDS). We hypothesize that manipulation of either modality will lead to dis-harmony between the two modalities, eg, loss of lip-sync, unnatural facial and lip movements, etc. MDS is computed as an aggregate of dissimilarity scores between audio and visual segments in a video. Discriminative features are learnt for the audio and visual channels in a chunk-wise manner, employing the cross-entropy loss for individual modalities, and a contrastive loss that models inter-modality similarity. Extensive experiments on the DFDC and DeepFake-TIMIT Datasets show that our approach outperforms the state-of-the-art by up to 7%. We also demonstrate temporal forgery localization, and show how our technique identifies the manipulated video segments.