 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Personalized Federated Learning
Jun 27, 2022

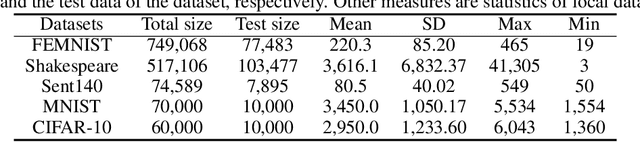

Federated learning is a distributed machine learning approach in which a single server and multiple clients collaboratively build machine learning models without sharing datasets on clients. A challenging issue of federated learning is data heterogeneity (i.e., data distributions may differ across clients). To cope with this issue, numerous federated learning methods aim at personalized federated learning and build optimized models for clients. Whereas existing studies empirically evaluated their own methods, the experimental settings (e.g., comparison methods, datasets, and client setting) in these studies differ from each other, and it is unclear which personalized federate learning method achieves the best performance and how much progress can be made by using these methods instead of standard (i.e., non-personalized) federated learning. In this paper, we benchmark the performance of existing personalized federated learning through comprehensive experiments to evaluate the characteristics of each method. Our experimental study shows that (1) there are no champion methods, (2) large data heterogeneity often leads to high accurate predictions, and (3) standard federated learning methods (e.g. FedAvg) with fine-tuning often outperform personalized federated learning methods. We open our benchmark tool FedBench for researchers to conduct experimental studies with various experimental settings.
FedMe: Federated Learning via Model Exchange
Oct 15, 2021



Federated learning is a distributed machine learning method in which a single server and multiple clients collaboratively build machine learning models without sharing datasets on clients. Numerous methods have been proposed to cope with the data heterogeneity issue in federated learning. Existing solutions require a model architecture tuned by the central server, yet a major technical challenge is that it is difficult to tune the model architecture due to the absence of local data on the central server. In this paper, we propose Federated learning via Model exchange (FedMe), which personalizes models with automatic model architecture tuning during the learning process. The novelty of FedMe lies in its learning process: clients exchange their models for model architecture tuning and model training. First, to optimize the model architectures for local data, clients tune their own personalized models by comparing to exchanged models and picking the one that yields the best performance. Second, clients train both personalized models and exchanged models by using deep mutual learning, in spite of different model architectures across the clients. We perform experiments on three real datasets and show that FedMe outperforms state-of-the-art federated learning methods while tuning model architectures automatically.