 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Transformer-Based Near- and Far-Field THz Wideband Channel Estimation for UM-MIMO
May 12, 2026The integration of terahertz communications and ultra-massive multiple-input multiple-output (UM-MIMO) systems in 6G networks is motivated by their ability to enable unprecedented data rates, mitigate spectrum congestion, and enhance overall network performance. However, the enlarged antenna apertures and higher carrier frequencies in these systems increase the Rayleigh distance, causing users to span both the near-field and conventional far-field regions. Accurate spatial precoding thus requires exact channel estimation at the base station - a task made more challenging by the hybrid coexistence of near- and far-field effects and the limited number of digital chains available in hybrid beamforming architectures. In this paper, we propose a block recurrent transformer model to address this challenge. We demonstrate that a single transformer block equipped with state memory can be trained once and then iteratively applied for hybrid-field channel estimation. Furthermore, we train the model such that it generalizes to wireless channels with varying scatterer distances, different numbers of propagation paths, and wideband operation. Simulation results show that the proposed method achieves performance gains of approximately 5 dB and 7.5 dB in normalized mean squared error (NMSE) over state-of-the-art solutions in narrowband and wideband scenarios, respectively.
* 15 pages, 15 figures
Information Bottleneck Analysis of Deep Neural Networks via Lossy Compression
May 13, 2023



The Information Bottleneck (IB) principle offers an information-theoretic framework for analyzing the training process of deep neural networks (DNNs). Its essence lies in tracking the dynamics of two mutual information (MI) values: one between the hidden layer and the class label, and the other between the hidden layer and the DNN input. According to the hypothesis put forth by Shwartz-Ziv and Tishby (2017), the training process consists of two distinct phases: fitting and compression. The latter phase is believed to account for the good generalization performance exhibited by DNNs. Due to the challenging nature of estimating MI between high-dimensional random vectors, this hypothesis has only been verified for toy NNs or specific types of NNs, such as quantized NNs and dropout NNs. In this paper, we introduce a comprehensive framework for conducting IB analysis of general NNs. Our approach leverages the stochastic NN method proposed by Goldfeld et al. (2019) and incorporates a compression step to overcome the obstacles associated with high dimensionality. In other words, we estimate the MI between the compressed representations of high-dimensional random vectors. The proposed method is supported by both theoretical and practical justifications. Notably, we demonstrate the accuracy of our estimator through synthetic experiments featuring predefined MI values. Finally, we perform IB analysis on a close-to-real-scale convolutional DNN, which reveals new features of the MI dynamics.
Soft-Output Deep Neural Network-Based Decoding
Apr 18, 2023

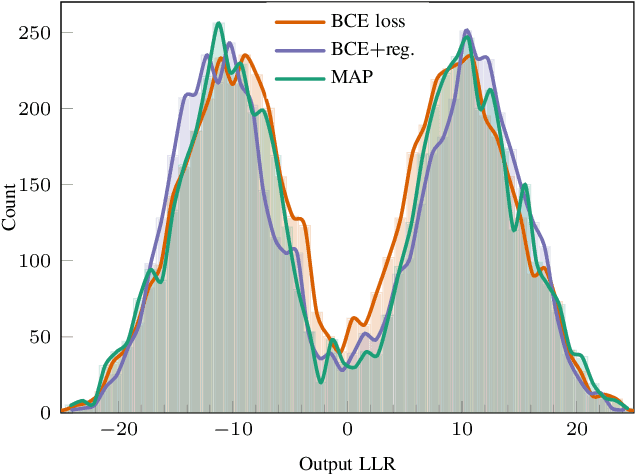

Deep neural network (DNN)-based channel decoding is widely considered in the literature. The existing solutions are investigated for the case of hard output, i.e. when the decoder returns the estimated information word. At the same time, soft-output decoding is of critical importance for iterative receivers and decoders. In this paper, we focus on the soft-output DNN-based decoding problem. We start with the syndrome-based approach proposed by Bennatan et al. (2018) and modify it to provide soft output in the AWGN channel. The new decoder can be considered as an approximation of the MAP decoder with smaller computation complexity. We discuss various regularization functions for joint DNN-MAP training and compare the resulting distributions for [64, 45] BCH code. Finally, to demonstrate the soft-output quality we consider the turbo-product code with [64, 45] BCH codes as row and column codes. We show that the resulting DNN-based scheme is very close to the MAP-based performance and significantly outperforms the solution based on the Chase decoder. We come to the conclusion that the new method is prospective for the challenging problem of DNN-based decoding of long codes consisting of short component codes.