 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Scheduling and Preemption on the Efficiency of LLM Inference Serving
Nov 12, 2024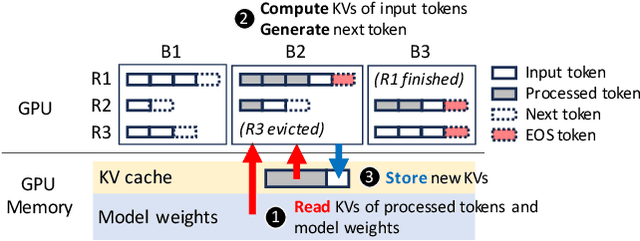
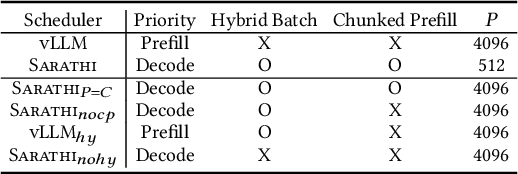

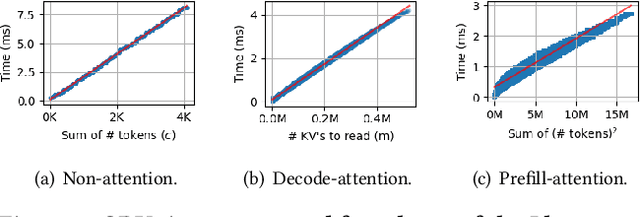
The growing usage of Large Language Models (LLMs) highlights the demands and challenges in scalable LLM inference systems, affecting deployment and development processes. On the deployment side, there is a lack of comprehensive analysis on the conditions under which a particular scheduler performs better or worse, with performance varying substantially across different schedulers, hardware, models, and workloads. Manually testing each configuration on GPUs can be prohibitively expensive. On the development side, unpredictable performance and unknown upper limits can lead to inconclusive trial-and-error processes, consuming resources on ideas that end up ineffective. To address these challenges, we introduce INFERMAX, an analytical framework that uses inference cost models to compare various schedulers, including an optimal scheduler formulated as a constraint satisfaction problem (CSP) to establish an upper bound on performance. Our framework offers in-depth analysis and raises essential questions, challenging assumptions and exploring opportunities for more efficient scheduling. Notably, our findings indicate that preempting requests can reduce GPU costs by 30% compared to avoiding preemptions at all. We believe our methods and insights will facilitate the cost-effective deployment and development of scalable, efficient inference systems and pave the way for cost-based scheduling.