 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrustworthy and Efficient LLMs Meet Databases
Dec 23, 2024In the rapidly evolving AI era with large language models (LLMs) at the core, making LLMs more trustworthy and efficient, especially in output generation (inference), has gained significant attention. This is to reduce plausible but faulty LLM outputs (a.k.a hallucinations) and meet the highly increased inference demands. This tutorial explores such efforts and makes them transparent to the database community. Understanding these efforts is essential in harnessing LLMs in database tasks and adapting database techniques to LLMs. Furthermore, we delve into the synergy between LLMs and databases, highlighting new opportunities and challenges in their intersection. This tutorial aims to share with database researchers and practitioners essential concepts and strategies around LLMs, reduce the unfamiliarity of LLMs, and inspire joining in the intersection between LLMs and databases.
The Effect of Scheduling and Preemption on the Efficiency of LLM Inference Serving
Nov 12, 2024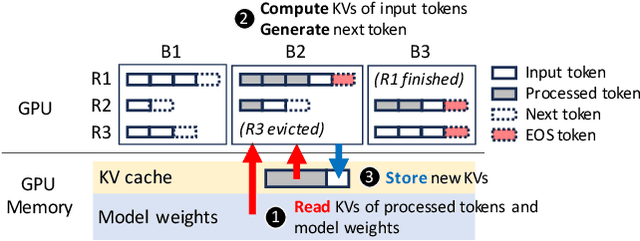
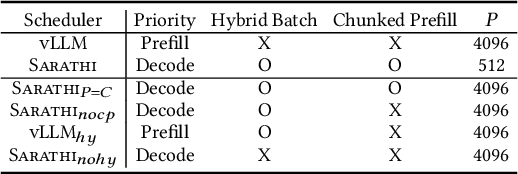

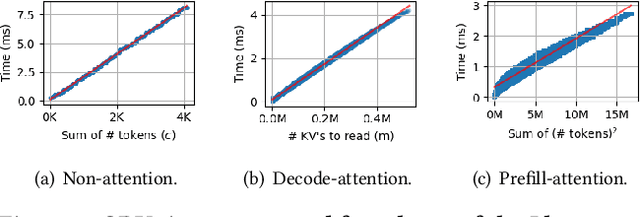
The growing usage of Large Language Models (LLMs) highlights the demands and challenges in scalable LLM inference systems, affecting deployment and development processes. On the deployment side, there is a lack of comprehensive analysis on the conditions under which a particular scheduler performs better or worse, with performance varying substantially across different schedulers, hardware, models, and workloads. Manually testing each configuration on GPUs can be prohibitively expensive. On the development side, unpredictable performance and unknown upper limits can lead to inconclusive trial-and-error processes, consuming resources on ideas that end up ineffective. To address these challenges, we introduce INFERMAX, an analytical framework that uses inference cost models to compare various schedulers, including an optimal scheduler formulated as a constraint satisfaction problem (CSP) to establish an upper bound on performance. Our framework offers in-depth analysis and raises essential questions, challenging assumptions and exploring opportunities for more efficient scheduling. Notably, our findings indicate that preempting requests can reduce GPU costs by 30% compared to avoiding preemptions at all. We believe our methods and insights will facilitate the cost-effective deployment and development of scalable, efficient inference systems and pave the way for cost-based scheduling.
PixelsDB: Serverless and Natural-Language-Aided Data Analytics with Flexible Service Levels and Prices
May 30, 2024Serverless query processing has become increasingly popular due to its advantages, including automated hardware and software management, high elasticity, and pay-as-you-go pricing. For users who are not system experts, serverless query processing greatly reduces the cost of owning a data analytic system. However, it is still a significant challenge for non-expert users to transform their complex and evolving data analytic needs into proper SQL queries and select a serverless query engine that delivers satisfactory performance and price for each type of query. This paper presents PixelsDB, an open-source data analytic system that allows users who lack system or SQL expertise to explore data efficiently. It allows users to generate and debug SQL queries using a natural language interface powered by fine-tuned language models. The queries are then executed by a serverless query engine that offers varying prices for different service levels on query urgency. The service levels are natively supported by dedicated architecture design and heterogeneous resource scheduling that can apply cost-efficient resources to process non-urgent queries. We envision that the combination of a serverless paradigm, a natural-language-aided interface, and flexible service levels and prices will substantially improve the user experience in data analysis.
Efficient Data Access Paths for Mixed Vector-Relational Search
Mar 23, 2024The rapid growth of machine learning capabilities and the adoption of data processing methods using vector embeddings sparked a great interest in creating systems for vector data management. While the predominant approach of vector data management is to use specialized index structures for fast search over the entirety of the vector embeddings, once combined with other (meta)data, the search queries can also become selective on relational attributes - typical for analytical queries. As using vector indexes differs from traditional relational data access, we revisit and analyze alternative access paths for efficient mixed vector-relational search. We first evaluate the accurate but exhaustive scan-based search and propose hardware optimizations and alternative tensor-based formulation and batching to offset the cost. We outline the complex access-path design space, primarily driven by relational selectivity, and the decisions to consider when selecting an exhaustive scan-based search against an approximate index-based approach. Since the vector index primarily avoids expensive computation across the entire dataset, contrary to the common relational knowledge, it is better to scan at lower selectivity and probe at higher, with a cross-point between the two approaches dictated by data dimensionality and the number of concurrent search queries.
Context-Enhanced Relational Operators with Vector Embeddings
Dec 03, 2023



Collecting data, extracting value, and combining insights from relational and context-rich multi-modal sources in data processing pipelines presents a challenge for traditional relational DBMS. While relational operators allow declarative and optimizable query specification, they are limited to data transformations unsuitable for capturing or analyzing context. On the other hand, representation learning models can map context-rich data into embeddings, allowing machine-automated context processing but requiring imperative data transformation integration with the analytical query. To bridge this dichotomy, we present a context-enhanced relational join and introduce an embedding operator composable with relational operators. This enables hybrid relational and context-rich vector data processing, with algebraic equivalences compatible with relational algebra and corresponding logical and physical optimizations. We investigate model-operator interaction with vector data processing and study the characteristics of the E-join operator. Using an example of string embeddings, we demonstrate enabling hybrid context-enhanced processing on relational join operators with vector embeddings. The importance of holistic optimization, from logical to physical, is demonstrated in an order of magnitude execution time improvement.
Analytical Engines With Context-Rich Processing: Towards Efficient Next-Generation Analytics
Dec 14, 2022As modern data pipelines continue to collect, produce, and store a variety of data formats, extracting and combining value from traditional and context-rich sources such as strings, text, video, audio, and logs becomes a manual process where such formats are unsuitable for RDBMS. To tap into the dark data, domain experts analyze and extract insights and integrate them into the data repositories. This process can involve out-of-DBMS, ad-hoc analysis, and processing resulting in ETL, engineering effort, and suboptimal performance. While AI systems based on ML models can automate the analysis process, they often further generate context-rich answers. Using multiple sources of truth, for either training the models or in the form of knowledge bases, further exacerbates the problem of consolidating the data of interest. We envision an analytical engine co-optimized with components that enable context-rich analysis. Firstly, as the data from different sources or resulting from model answering cannot be cleaned ahead of time, we propose using online data integration via model-assisted similarity operations. Secondly, we aim for a holistic pipeline cost- and rule-based optimization across relational and model-based operators. Thirdly, with increasingly heterogeneous hardware and equally heterogeneous workloads ranging from traditional relational analytics to generative model inference, we envision a system that just-in-time adapts to the complex analytical query requirements. To solve increasingly complex analytical problems, ML offers attractive solutions that must be combined with traditional analytical processing and benefit from decades of database community research to achieve scalability and performance effortless for the end user.