 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-LinkNet: Learning Contextual Inpainting Across Latent Space of Generative Adversarial Network
Jan 02, 2022
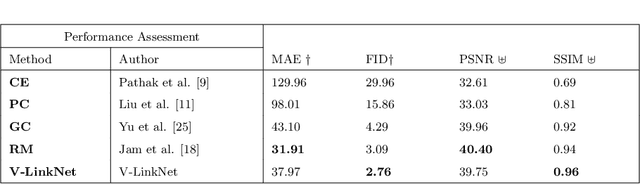

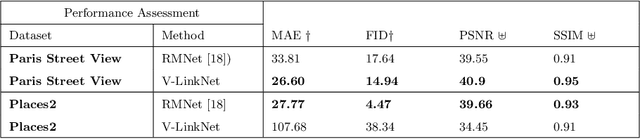
Deep learning methods outperform traditional methods in image inpainting. In order to generate contextual textures, researchers are still working to improve on existing methods and propose models that can extract, propagate, and reconstruct features similar to ground-truth regions. Furthermore, the lack of a high-quality feature transfer mechanism in deeper layers contributes to persistent aberrations on generated inpainted regions. To address these limitations, we propose the V-LinkNet cross-space learning strategy network. To improve learning on contextualised features, we design a loss model that employs both encoders. In addition, we propose a recursive residual transition layer (RSTL). The RSTL extracts high-level semantic information and propagates it down layers. Finally, we compare inpainting performance on the same face with different masks and on different faces with the same masks. To improve image inpainting reproducibility, we propose a standard protocol to overcome biases with various masks and images. We investigate the V-LinkNet components using experimental methods. Our result surpasses the state of the art when evaluated on the CelebA-HQ with the standard protocol. In addition, our model can generalise well when evaluated on Paris Street View, and Places2 datasets with the standard protocol.
Foreground-guided Facial Inpainting with Fidelity Preservation
May 07, 2021
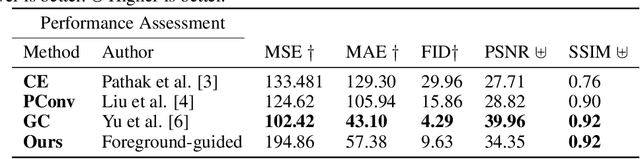
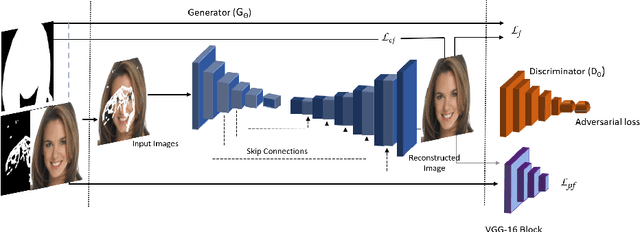
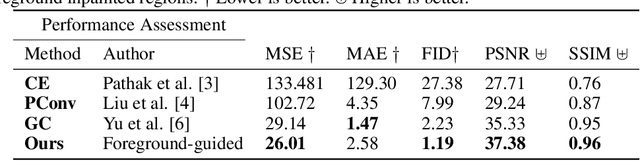
Facial image inpainting, with high-fidelity preservation for image realism, is a very challenging task. This is due to the subtle texture in key facial features (component) that are not easily transferable. Many image inpainting techniques have been proposed with outstanding capabilities and high quantitative performances recorded. However, with facial inpainting, the features are more conspicuous and the visual quality of the blended inpainted regions are more important qualitatively. Based on these facts, we design a foreground-guided facial inpainting framework that can extract and generate facial features using convolutional neural network layers. It introduces the use of foreground segmentation masks to preserve the fidelity. Specifically, we propose a new loss function with semantic capability reasoning of facial expressions, natural and unnatural features (make-up). We conduct our experiments using the CelebA-HQ dataset, segmentation masks from CelebAMask-HQ (for foreground guidance) and Quick Draw Mask (for missing regions). Our proposed method achieved comparable quantitative results when compare to the state of the art but qualitatively, it demonstrated high-fidelity preservation of facial components.
R-MNet: A Perceptual Adversarial Network for Image Inpainting
Aug 11, 2020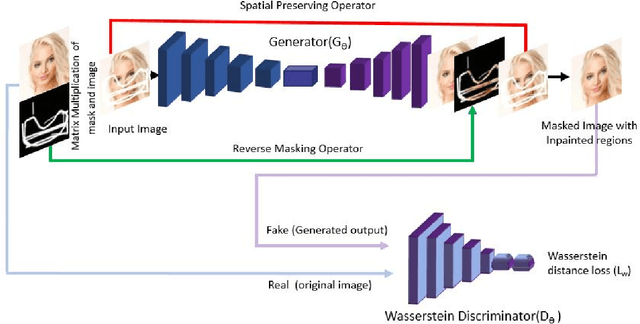
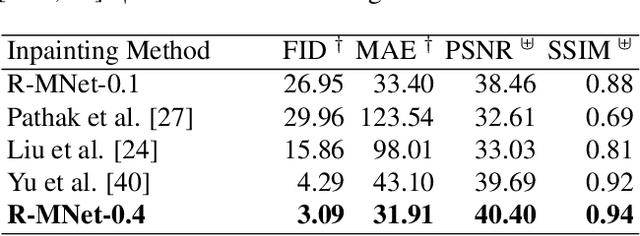
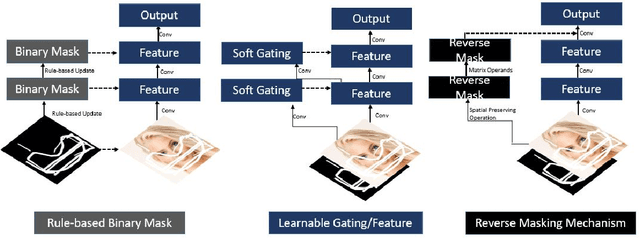

Facial image inpainting is a problem that is widely studied, and in recent years the introduction of Generative Adversarial Networks, has led to improvements in the field. Unfortunately some issues persists, in particular when blending the missing pixels with the visible ones. We address the problem by proposing a Wasserstein GAN combined with a new reverse mask operator, namely Reverse Masking Network (R-MNet), a perceptual adversarial network for image inpainting. The reverse mask operator transfers the reverse masked image to the end of the encoder-decoder network leaving only valid pixels to be inpainted. Additionally, we propose a new loss function computed in feature space to target only valid pixels combined with adversarial training. These then capture data distributions and generate images similar to those in the training data with achieved realism (realistic and coherent) on the output images. We evaluate our method on publicly available dataset, and compare with state-of-the-art methods. We show that our method is able to generalize to high-resolution inpainting task, and further show more realistic outputs that are plausible to the human visual system when compared with the state-of-the-art methods.
Symmetric Skip Connection Wasserstein GAN for High-Resolution Facial Image Inpainting
Jan 11, 2020
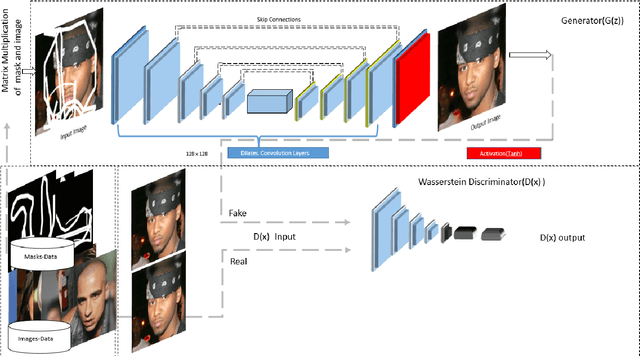
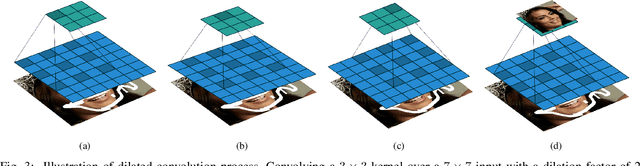

We propose a Symmetric Skip Connection Wasserstein Generative Adversarial Network (S-WGAN) for high-resolution facial image inpainting. The architecture is an encoder-decoder with convolutional blocks, linked by skip connections. The encoder is a feature extractor that captures data abstractions of an input image to learn an end-to-end mapping from an input (binary masked image) to the ground-truth. The decoder uses the learned abstractions to reconstruct the image. With skip connections, S-WGAN transfers image details to the decoder. Also, we propose a Wasserstein-Perceptual loss function to preserve colour and maintain realism on a reconstructed image. We evaluate our method and the state-of-the-art methods on CelebA-HQ dataset. Our results show S-WGAN produces sharper and more realistic images when visually compared with other methods. The quantitative measures show our proposed S-WGAN achieves the best Structure Similarity Index Measure of 0.94.