 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible Prefrontal Control over Hippocampal Episodic Memory for Goal-Directed Generalization
Mar 04, 2025Many tasks require flexibly modifying perception and behavior based on current goals. Humans can retrieve episodic memories from days to years ago, using them to contextualize and generalize behaviors across novel but structurally related situations. The brain's ability to control episodic memories based on task demands is often attributed to interactions between the prefrontal cortex (PFC) and hippocampus (HPC). We propose a reinforcement learning model that incorporates a PFC-HPC interaction mechanism for goal-directed generalization. In our model, the PFC learns to generate query-key representations to encode and retrieve goal-relevant episodic memories, modulating HPC memories top-down based on current task demands. Moreover, the PFC adapts its encoding and retrieval strategies dynamically when faced with multiple goals presented in a blocked, rather than interleaved, manner. Our results show that: (1) combining working memory with selectively retrieved episodic memory allows transfer of decisions among similar environments or situations, (2) top-down control from PFC over HPC improves learning of arbitrary structural associations between events for generalization to novel environments compared to a bottom-up sensory-driven approach, and (3) the PFC encodes generalizable representations during both encoding and retrieval of goal-relevant memories, whereas the HPC exhibits event-specific representations. Together, these findings highlight the importance of goal-directed prefrontal control over hippocampal episodic memory for decision-making in novel situations and suggest a computational mechanism by which PFC-HPC interactions enable flexible behavior.
Meta-Learning to Explore via Memory Density Feedback
Mar 04, 2025Exploration algorithms for reinforcement learning typically replace or augment the reward function with an additional ``intrinsic'' reward that trains the agent to seek previously unseen states of the environment. Here, we consider an exploration algorithm that exploits meta-learning, or learning to learn, such that the agent learns to maximize its exploration progress within a single episode, even between epochs of training. The agent learns a policy that aims to minimize the probability density of new observations with respect to all of its memories. In addition, it receives as feedback evaluations of the current observation density and retains that feedback in a recurrent network. By remembering trajectories of density, the agent learns to navigate a complex and growing landscape of familiarity in real-time, allowing it to maximize its exploration progress even in completely novel states of the environment for which its policy has not been trained.
Locally Learned Synaptic Dropout for Complete Bayesian Inference
Nov 29, 2021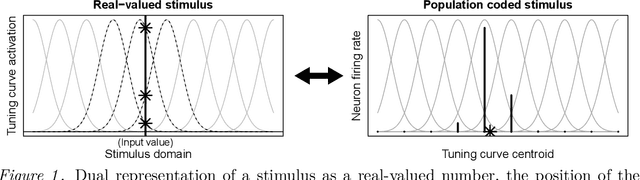
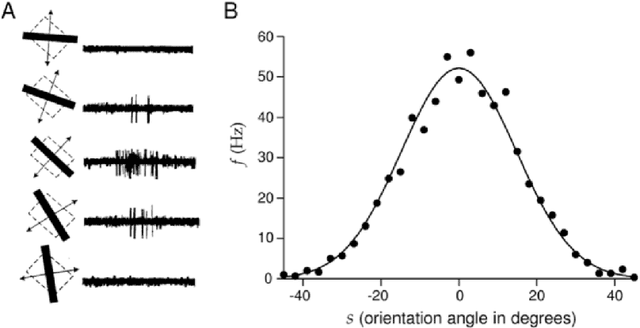
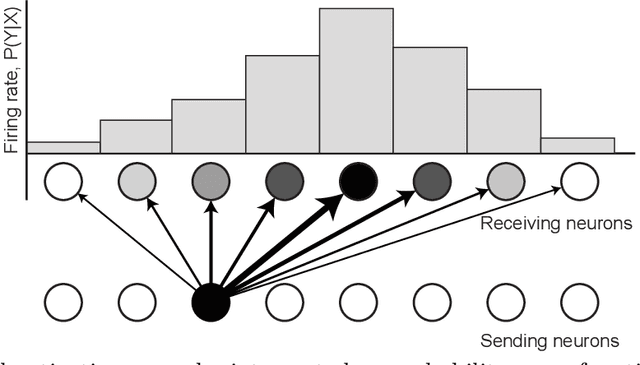
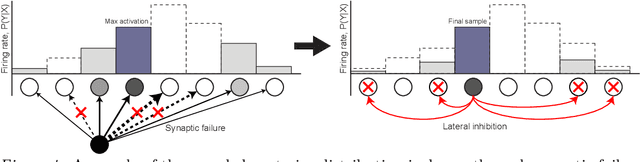
The Bayesian brain hypothesis postulates that the brain accurately operates on statistical distributions according to Bayes' theorem. The random failure of presynaptic vesicles to release neurotransmitters may allow the brain to sample from posterior distributions of network parameters, interpreted as epistemic uncertainty. It has not been shown previously how random failures might allow networks to sample from observed distributions, also known as aleatoric or residual uncertainty. Sampling from both distributions enables probabilistic inference, efficient search, and creative or generative problem solving. We demonstrate that under a population-code based interpretation of neural activity, both types of distribution can be represented and sampled with synaptic failure alone. We first define a biologically constrained neural network and sampling scheme based on synaptic failure and lateral inhibition. Within this framework, we derive drop-out based epistemic uncertainty, then prove an analytic mapping from synaptic efficacy to release probability that allows networks to sample from arbitrary, learned distributions represented by a receiving layer. Second, our result leads to a local learning rule by which synapses adapt their release probabilities. Our result demonstrates complete Bayesian inference, related to the variational learning method of dropout, in a biologically constrained network using only locally-learned synaptic failure rates.