 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Neural Language Modelling with Syllables
Oct 24, 2020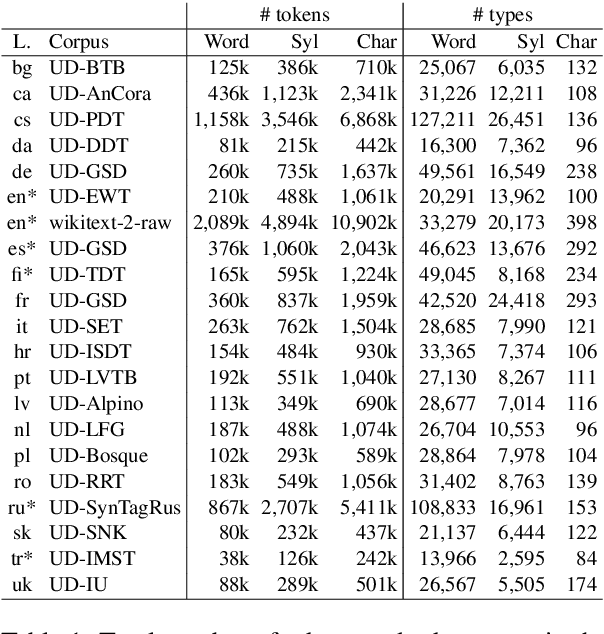

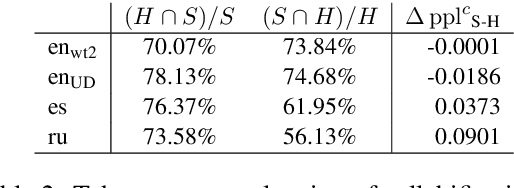

Language modelling is regularly analysed at word, subword or character units, but syllables are seldom used. Syllables provide shorter sequences than characters, they can be extracted with rules, and their segmentation typically requires less specialised effort than identifying morphemes. We reconsider syllables for an open-vocabulary generation task in 20 languages. We use rule-based syllabification methods for five languages and address the rest with a hyphenation tool, which behaviour as syllable proxy is validated. With a comparable perplexity, we show that syllables outperform characters, annotated morphemes and unsupervised subwords. Finally, we also study the overlapping of syllables concerning other subword pieces and discuss some limitations and opportunities.
Efficient strategies for hierarchical text classification: External knowledge and auxiliary tasks
May 22, 2020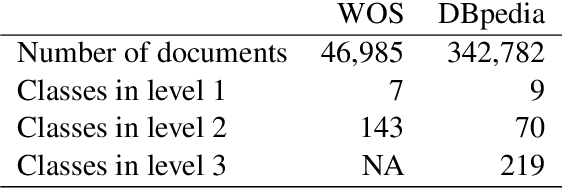

In hierarchical text classification, we perform a sequence of inference steps to predict the category of a document from top to bottom of a given class taxonomy. Most of the studies have focused on developing novels neural network architectures to deal with the hierarchical structure, but we prefer to look for efficient ways to strengthen a baseline model. We first define the task as a sequence-to-sequence problem. Afterwards, we propose an auxiliary synthetic task of bottom-up-classification. Then, from external dictionaries, we retrieve textual definitions for the classes of all the hierarchy's layers, and map them into the word vector space. We use the class-definition embeddings as an additional input to condition the prediction of the next layer and in an adapted beam search. Whereas the modified search did not provide large gains, the combination of the auxiliary task and the additional input of class-definitions significantly enhance the classification accuracy. With our efficient approaches, we outperform previous studies, using a drastically reduced number of parameters, in two well-known English datasets.