 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Neural Language Modelling with Syllables
Paper and Code
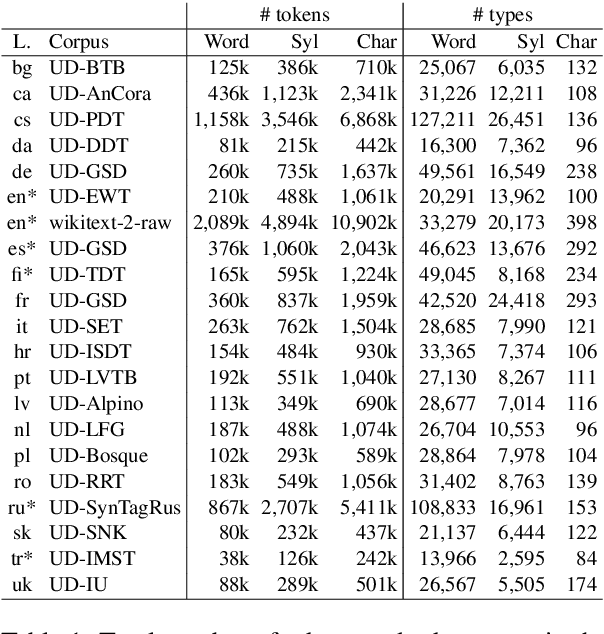

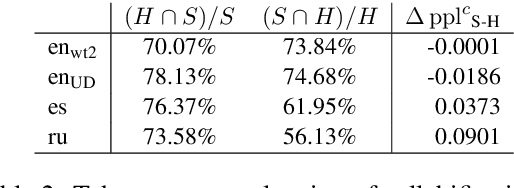

Language modelling is regularly analysed at word, subword or character units, but syllables are seldom used. Syllables provide shorter sequences than characters, they can be extracted with rules, and their segmentation typically requires less specialised effort than identifying morphemes. We reconsider syllables for an open-vocabulary generation task in 20 languages. We use rule-based syllabification methods for five languages and address the rest with a hyphenation tool, which behaviour as syllable proxy is validated. With a comparable perplexity, we show that syllables outperform characters, annotated morphemes and unsupervised subwords. Finally, we also study the overlapping of syllables concerning other subword pieces and discuss some limitations and opportunities.