 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViewpoint and Topic Modeling of Current Events
Aug 14, 2016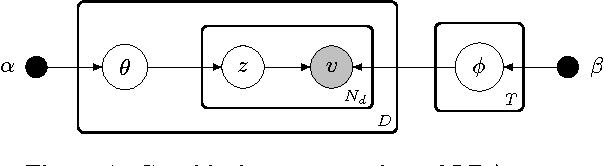

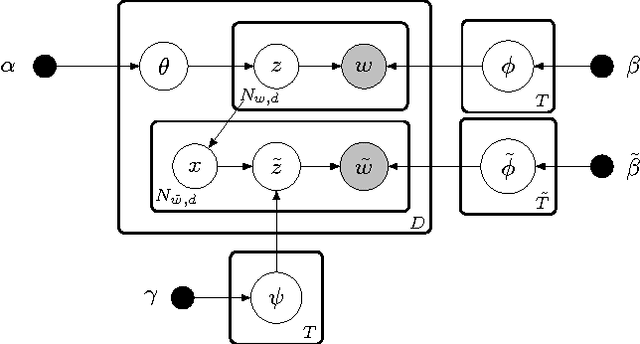

There are multiple sides to every story, and while statistical topic models have been highly successful at topically summarizing the stories in corpora of text documents, they do not explicitly address the issue of learning the different sides, the viewpoints, expressed in the documents. In this paper, we show how these viewpoints can be learned completely unsupervised and represented in a human interpretable form. We use a novel approach of applying CorrLDA2 for this purpose, which learns topic-viewpoint relations that can be used to form groups of topics, where each group represents a viewpoint. A corpus of documents about the Israeli-Palestinian conflict is then used to demonstrate how a Palestinian and an Israeli viewpoint can be learned. By leveraging the magnitudes and signs of the feature weights of a linear SVM, we introduce a principled method to evaluate associations between topics and viewpoints. With this, we demonstrate, both quantitatively and qualitatively, that the learned topic groups are contextually coherent, and form consistently correct topic-viewpoint associations.