 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetric-based multimodal meta-learning for human movement identification via footstep recognition
Nov 15, 2021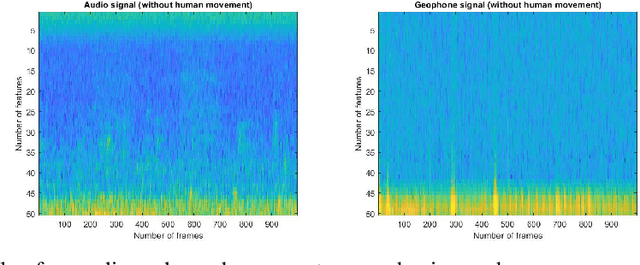

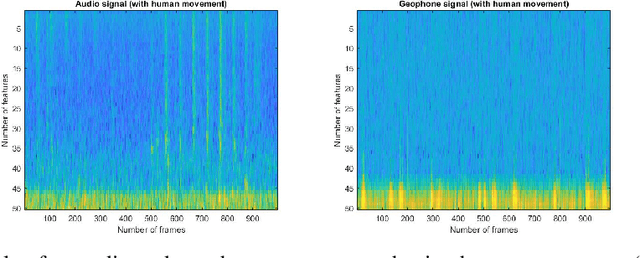
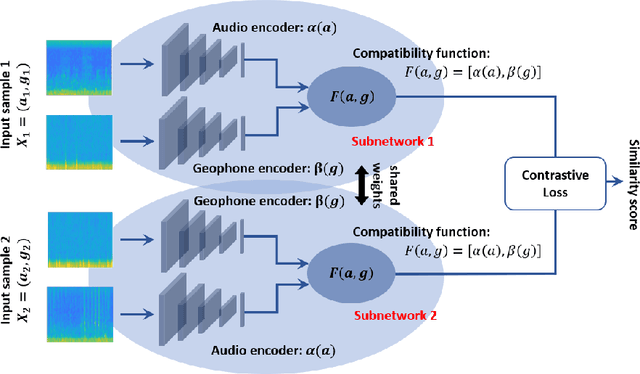
We describe a novel metric-based learning approach that introduces a multimodal framework and uses deep audio and geophone encoders in siamese configuration to design an adaptable and lightweight supervised model. This framework eliminates the need for expensive data labeling procedures and learns general-purpose representations from low multisensory data obtained from omnipresent sensing systems. These sensing systems provide numerous applications and various use cases in activity recognition tasks. Here, we intend to explore the human footstep movements from indoor environments and analyze representations from a small self-collected dataset of acoustic and vibration-based sensors. The core idea is to learn plausible similarities between two sensory traits and combining representations from audio and geophone signals. We present a generalized framework to learn embeddings from temporal and spatial features extracted from audio and geophone signals. We then extract the representations in a shared space to maximize the learning of a compatibility function between acoustic and geophone features. This, in turn, can be used effectively to carry out a classification task from the learned model, as demonstrated by assigning high similarity to the pairs with a human footstep movement and lower similarity to pairs containing no footstep movement. Performance analyses show that our proposed multimodal framework achieves a 19.99\% accuracy increase (in absolute terms) and avoided overfitting on the evaluation set when the training samples were increased from 200 pairs to just 500 pairs while satisfactorily learning the audio and geophone representations. Our results employ a metric-based contrastive learning approach for multi-sensor data to mitigate the impact of data scarcity and perform human movement identification with limited data size.