 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeyGS: A Keyframe-Centric Gaussian Splatting Method for Monocular Image Sequences
Dec 30, 2024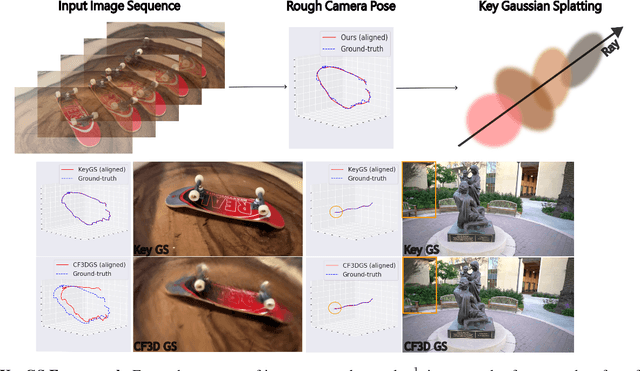



Reconstructing high-quality 3D models from sparse 2D images has garnered significant attention in computer vision. Recently, 3D Gaussian Splatting (3DGS) has gained prominence due to its explicit representation with efficient training speed and real-time rendering capabilities. However, existing methods still heavily depend on accurate camera poses for reconstruction. Although some recent approaches attempt to train 3DGS models without the Structure-from-Motion (SfM) preprocessing from monocular video datasets, these methods suffer from prolonged training times, making them impractical for many applications. In this paper, we present an efficient framework that operates without any depth or matching model. Our approach initially uses SfM to quickly obtain rough camera poses within seconds, and then refines these poses by leveraging the dense representation in 3DGS. This framework effectively addresses the issue of long training times. Additionally, we integrate the densification process with joint refinement and propose a coarse-to-fine frequency-aware densification to reconstruct different levels of details. This approach prevents camera pose estimation from being trapped in local minima or drifting due to high-frequency signals. Our method significantly reduces training time from hours to minutes while achieving more accurate novel view synthesis and camera pose estimation compared to previous methods.
Personalized Head-Related Transfer Function Prediction Based on Spatial Grouping
Dec 10, 2024The head-related transfer function (HRTF) characterizes the frequency response of the sound traveling path between a specific location and the ear. When it comes to estimating HRTFs by neural network models, angle-specific models greatly outperform global models but demand high computational resources. To balance the computational resource and performance, we propose a method by grouping HRTF data spatially to reduce variance within each subspace. HRTF predicting neural network is then trained for each subspace. Simulation results show the proposed method performs better than global models and angle-specific models by using different grouping strategies at the ipsilateral and contralateral sides.