 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBaby Physical Safety Monitoring in Smart Home Using Action Recognition System
Oct 22, 2022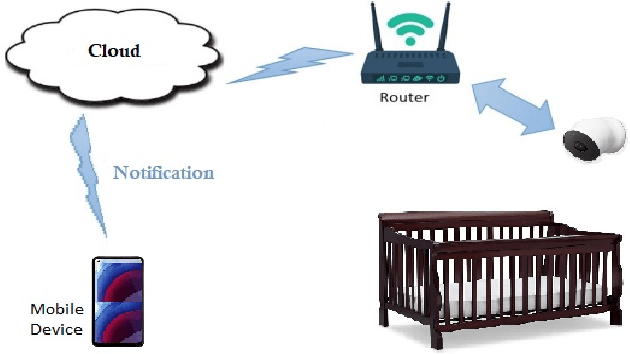



Humans are able to intuitively deduce actions that took place between two states in observations via deductive reasoning. This is because the brain operates on a bidirectional communication model, which has radically improved the accuracy of recognition and prediction based on features connected to previous experiences. During the past decade, deep learning models for action recognition have significantly improved. However, deep neural networks struggle with these tasks on a smaller dataset for specific Action Recognition (AR) tasks. As with most action recognition tasks, the ambiguity of accurately describing activities in spatial-temporal data is a drawback that can be overcome by curating suitable datasets, including careful annotations and preprocessing of video data for analyzing various recognition tasks. In this study, we present a novel lightweight framework combining transfer learning techniques with a Conv2D LSTM layer to extract features from the pre-trained I3D model on the Kinetics dataset for a new AR task (Smart Baby Care) that requires a smaller dataset and less computational resources. Furthermore, we developed a benchmark dataset and an automated model that uses LSTM convolution with I3D (ConvLSTM-I3D) for recognizing and predicting baby activities in a smart baby room. Finally, we implemented video augmentation to improve model performance on the smart baby care task. Compared to other benchmark models, our experimental framework achieved better performance with less computational resources.