 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerceptual Quality Enhancement of Sound Field Synthesis Based on Combination of Pressure and Amplitude Matching
Jul 26, 2023A sound field synthesis method enhancing perceptual quality is proposed. Sound field synthesis using multiple loudspeakers enables spatial audio reproduction with a broad listening area; however, synthesis errors at high frequencies called spatial aliasing artifacts are unavoidable. To minimize these artifacts, we propose a method based on the combination of pressure and amplitude matching. On the basis of the human's auditory properties, synthesizing the amplitude distribution will be sufficient for horizontal sound localization. Furthermore, a flat amplitude response should be synthesized as much as possible to avoid coloration. Therefore, we apply amplitude matching, which is a method to synthesize the desired amplitude distribution with arbitrary phase distribution, for high frequencies and conventional pressure matching for low frequencies. Experimental results of numerical simulations and listening tests using a practical system indicated that the perceptual quality of the sound field synthesized by the proposed method was improved from that synthesized by pressure matching.
Weighted Pressure and Mode Matching for Sound Field Reproduction: Theoretical and Experimental Comparisons
Mar 23, 2023Two sound field reproduction methods, weighted pressure matching and weighted mode matching, are theoretically and experimentally compared. The weighted pressure and mode matching are a generalization of conventional pressure and mode matching, respectively. Both methods are derived by introducing a weighting matrix in the pressure and mode matching. The weighting matrix in the weighted pressure matching is defined on the basis of the kernel interpolation of the sound field from pressure at a discrete set of control points. In the weighted mode matching, the weighting matrix is defined by a regional integration of spherical wavefunctions. It is theoretically shown that the weighted pressure matching is a special case of the weighted mode matching by infinite-dimensional harmonic analysis for estimating expansion coefficients from pressure observations. The difference between the two methods are discussed through experiments.
Mean-square-error-based secondary source placement in sound field synthesis with prior information on desired field
Dec 10, 2021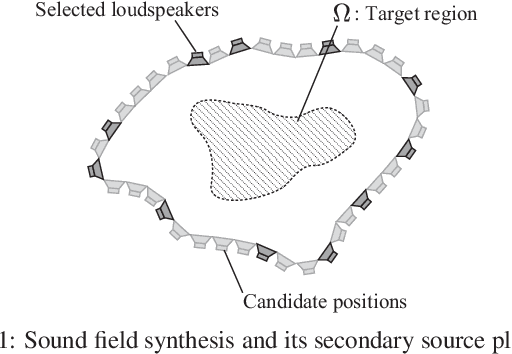
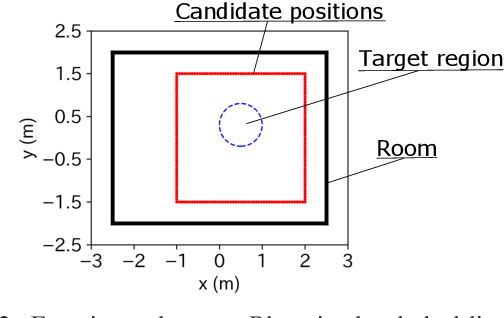
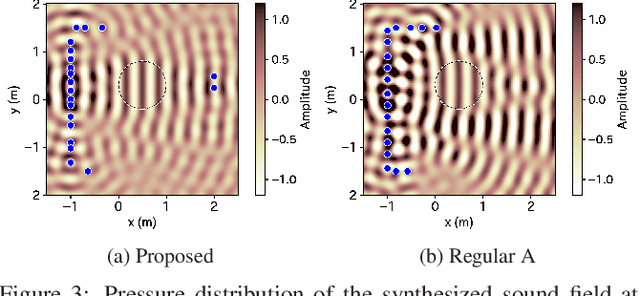
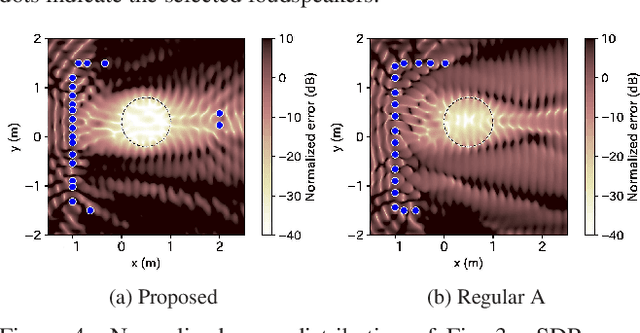
A method of optimizing secondary source placement in sound field synthesis is proposed. Such an optimization method will be useful when the allowable placement region and available number of loudspeakers are limited. We formulate a mean-square-error-based cost function, incorporating the statistical properties of possible desired sound fields, for general linear-least-squares-based sound field synthesis methods, including pressure matching and (weighted) mode matching, whereas most of the current methods are applicable only to the pressure-matching method. An efficient greedy algorithm for minimizing the proposed cost function is also derived. Numerical experiments indicated that a high reproduction accuracy can be achieved by the placement optimized by the proposed method compared with the empirically used regular placement.
Sound Field Reproduction With Weighted Mode Matching and Infinite-Dimensional Harmonic Analysis: An Experimental Evaluation
Nov 22, 2021
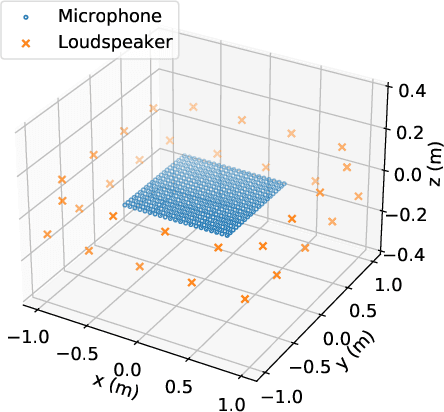

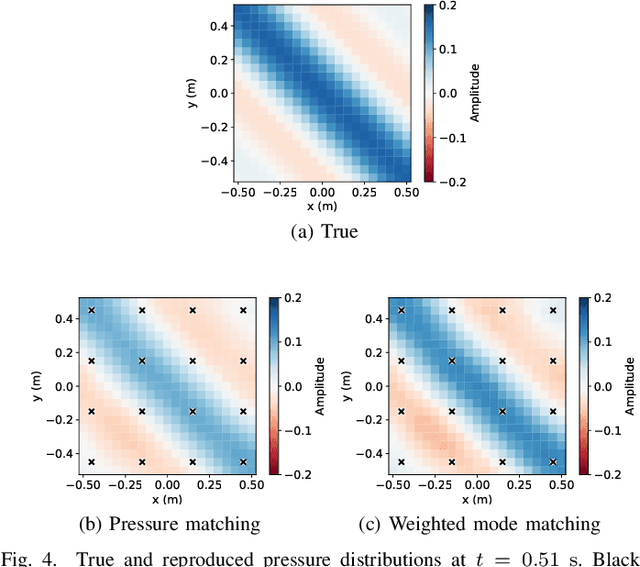
Sound field reproduction methods based on numerical optimization, which aim to minimize the error between synthesized and desired sound fields, are useful in many practical scenarios because of their flexibility in the array geometry of loudspeakers. However, the reproduction performance of these methods in a practical environment has not been sufficiently investigated. We evaluate weighted mode matching, which is a sound field reproduction method based on the spherical wavefunction expansion of the sound field, in comparison with conventional pressure matching. We also introduce a method of infinite-dimensional harmonic analysis for estimating the expansion coefficients of the sound field from microphone measurements. Experimental results indicated that weighted mode matching using the expansion coefficients of the transfer functions estimated by the infinite-dimensional harmonic analysis outperforms conventional pressure matching, especially when the number of microphones is small.
MeshRIR: A Dataset of Room Impulse Responses on Meshed Grid Points For Evaluating Sound Field Analysis and Synthesis Methods
Jun 21, 2021
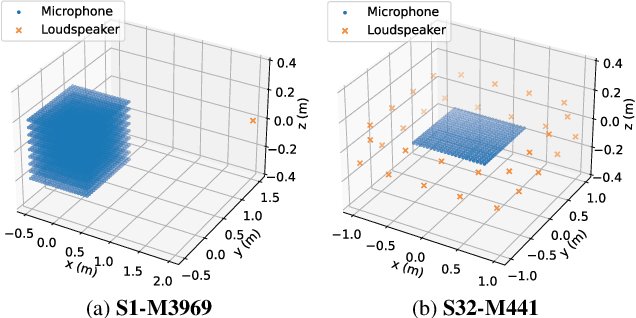
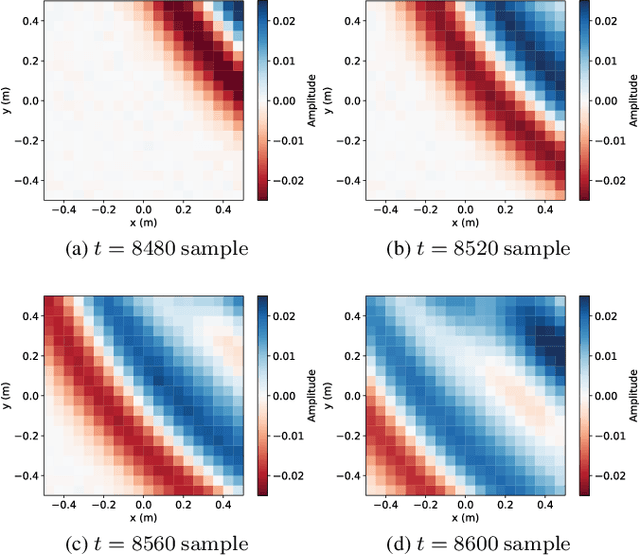
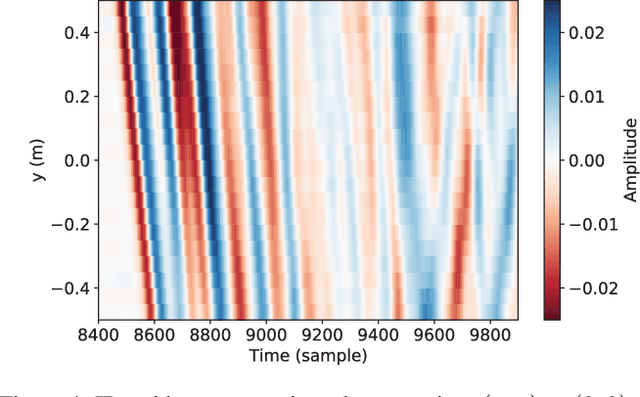
A new impulse response (IR) dataset called "MeshRIR" is introduced. Currently available datasets usually include IRs at an array of microphones from several source positions under various room conditions, which are basically designed for evaluating speech enhancement and distant speech recognition methods. On the other hand, methods of estimating or controlling spatial sound fields have been extensively investigated in recent years; however, the current IR datasets are not applicable to validating and comparing these methods because of the low spatial resolution of measurement points. MeshRIR consists of IRs measured at positions obtained by finely discretizing a spatial region. Two subdatasets are currently available: one consists of IRs in a three-dimensional cuboidal region from a single source, and the other consists of IRs in a two-dimensional square region from an array of 32 sources. Therefore, MeshRIR is suitable for evaluating sound field analysis and synthesis methods. This dataset is freely available at \url{https://sh01k.github.io/MeshRIR/} with some codes of sample applications.