 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational EP with Probabilistic Backpropagation for Bayesian Neural Networks
Mar 02, 2023I propose a novel approach for nonlinear Logistic regression using a two-layer neural network (NN) model structure with hierarchical priors on the network weights. I present a hybrid of expectation propagation called Variational Expectation Propagation approach (VEP) for approximate integration over the posterior distribution of the weights, the hierarchical scale parameters of the priors and zeta. Using a factorized posterior approximation I derive a computationally efficient algorithm, whose complexity scales similarly to an ensemble of independent sparse logistic models. The approach can be extended beyond standard activation functions and NN model structures to form flexible nonlinear binary predictors from multiple sparse linear models. I consider a hierarchical Bayesian model with logistic regression likelihood and a Gaussian prior distribution over the parameters called weights and hyperparameters. I work in the perspective of E step and M step for computing the approximating posterior and updating the parameters using the computed posterior respectively.
Image Reconstruction by Splitting Expectation Propagation Techniques from Iterative Inversion
Aug 25, 2022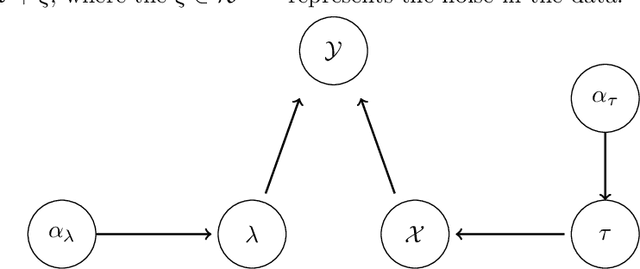



Reconstructing images from downsampled and noisy measurements, such as MRI and low dose Computed Tomography (CT), is a mathematically ill-posed inverse problem. We propose an easy-to-use reconstruction method based on Expectation Propagation (EP) techniques. We incorporate the Monte Carlo (MC) method, Markov Chain Monte Carlo (MCMC), and Alternating Direction Method of Multiplier (ADMM) algorithm into EP method to address the intractability issue encountered in EP. We demonstrate the approach on complex Bayesian models for image reconstruction. Our technique is applied to images from Gamma-camera scans. We compare EPMC, EP-MCMC, EP-ADMM methods with MCMC only. The metrics are the better image reconstruction, speed, and parameters estimation. Experiments with Gamma-camera imaging in real and simulated data show that our proposed method is convincingly less computationally expensive than MCMC and produces relatively a better image reconstruction.
Cluster Weighted Model Based on TSNE algorithm for High-Dimensional Data
Aug 02, 2022



Similar to many Machine Learning models, both accuracy and speed of the Cluster weighted models (CWMs) can be hampered by high-dimensional data, leading to previous works on a parsimonious technique to reduce the effect of "Curse of dimensionality" on mixture models. In this work, we review the background study of the cluster weighted models (CWMs). We further show that parsimonious technique is not sufficient for mixture models to thrive in the presence of huge high-dimensional data. We discuss a heuristic for detecting the hidden components by choosing the initial values of location parameters using the default values in the "FlexCWM" R package. We introduce a dimensionality reduction technique called T-distributed stochastic neighbor embedding (TSNE) to enhance the parsimonious CWMs in high-dimensional space. Originally, CWMs are suited for regression but for classification purposes, all multi-class variables are transformed logarithmically with some noise. The parameters of the model are obtained via expectation maximization algorithm. The effectiveness of the discussed technique is demonstrated using real data sets from different fields.